Tentando não ficar pobre antes de ficar rico criando uma Startup de serviços de inteligência artificial
Neste post, vou mostrar como utilizar um banco de dados vetorial para diminuir os custos com tokens do GPT em uma aplicação de perguntas e respostas. O banco de dados vetorial que eu escolhi foi o Pinecone, que permite armazenar e consultar vetores de alta dimensão de forma eficiente e escalável. A ideia é transformar as perguntas e as respostas em vetores usando um modelo de linguagem natural pré-treinado, como o modelo text-embedding-ada-002, e depois usar o Pinecone para encontrar as respostas mais similares às perguntas dos usuários.
Bancos de dados vetoriais podem oferecer melhores resultados de consultas de texto do que os bancos de dados SQL porque eles usam uma representação matemática dos dados chamada vetor, que permite medir a similaridade entre documentos e consultas usando operações como distância ou ângulo. Os bancos de dados SQL, por outro lado, usam uma linguagem de consulta estruturada (SQL) que pode ser limitada para pesquisar correspondências exatas ou difusas de palavras ou frases usando o comando CONTAINS. Além disso, os bancos de dados SQL podem exigir mais recursos e tempo para indexar e pesquisar grandes quantidades de dados de texto do que os bancos de dados vetoriais.
Para gerenciar as perguntas, eu usei o Firebase Firestore, um banco de dados NoSQL na nuvem que oferece sincronização em tempo real e suporte offline. Cada pergunta é armazenada em um documento com um identificador único e um campo para a resposta. O Firestore também permite criar funções na nuvem que são acionadas por eventos no banco de dados, como a criação, atualização ou exclusão de documentos. Eu usei uma Cloud Function para disparar um evento sempre que uma nova pergunta for cadastrada no Firestore. Essa função é responsável por enviar a pergunta para a API do ChatGPT, um serviço que usa o modelo GPT-3.5-turbo para gerar respostas conversacionais. O ChatGPT retorna a resposta em formato de texto, que é então convertida em um vetor usando o mesmo modelo de linguagem natural que foi usado para as perguntas. Esse vetor é enviado para o Pinecone, que armazena o vetor para futuras novas perguntas.
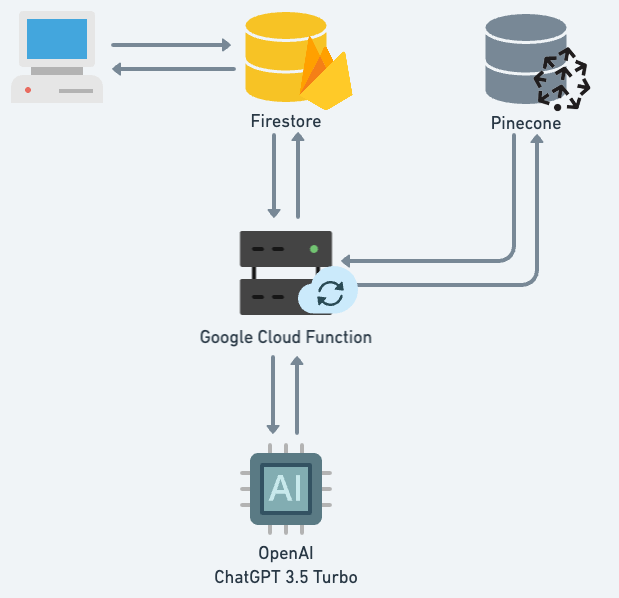
Uma vantagem de usar o Pinecone é que ele permite fazer consultas por similaridade usando os vetores das perguntas e das respostas. Assim, quando um usuário faz uma pergunta, eu não preciso enviar a pergunta para o ChatGPT e gastar tokens do GPT. Eu posso simplesmente converter a pergunta em um vetor e enviar para o Pinecone, que me retorna os identificadores dos vetores mais similares. Eu posso adotar uma resposta existente como a resposta da pergunta baseado no score de similaridade entre a nova pergunta e as perguntas que já foram feitas anteriormente. Isso reduz significativamente os custos com tokens do GPT, já que eu só preciso usar o ChatGPT para gerar respostas para perguntas novas ou muito diferentes das existentes.
Pode ser um grande desafio encontrar a resposta exata para a pergunta do usuário com base nas perguntas realizadas anteriormente. Exemplo: ‘Quanto custa 1kg do seu produto?’ ou ‘Quanto custa 1g do seu produto?’. Possivelmente o score do texto vetorizado das duas perguntas terá um score quase de 1.0. Isso pode ser um problema dependendo do seu interesse. Não cheguei a pensar em algo concreto para resolver esse problema, mas acredito que haja formas de contornar isso definindo diferenciações entre algumas palavras tais como ‘kilograma’ e ‘grama’.
Para fazer um comparativo entre o custo entre as consultas do Pinecone e o modelo GPT-3.5-turbo, eu usei os seguintes valores:
- O preço do Pinecone é de $0.096 / hora.
- O preço do ChatGPT é de $0.002 / 1K tokens do gpt-3.5-turbo.
Tokens são sequências comuns de caracteres encontrados no texto. O GPT processa o texto usando tokens e entende as relações estatísticas entre eles. Os tokens podem incluir espaços e até sub-palavras. O número máximo de tokens que o GPT pode receber como entrada depende do modelo e do tokenizador usados. Por exemplo, o modelo text-embedding-ada-002 usa o tokenizador cl100k_base e pode receber até 8191 tokens.
Cheguei a considerar o uso do Cloud Function como plataforma de hospedagem do meu código de consulta ao ChatGPT, mas me traria altos custos financeiros. Isso porque o Cloud Function cobra de acordo com o tempo de execução da sua função, além do número de invocações e dos recursos provisionados. Como a API do ChatGPT pode demorar para responder, dependendo da complexidade da sua consulta, você pode acabar pagando muito pelo tempo que a sua função fica aguardando a resposta da API.
Uma forma que encontrei de reduzir os custos com o ChatGPT é usar um web service no Render.com, onde é possível criar uma aplicação em Flask onde eu consegui utilizar threads para não aguardar a API do GPT responder antes de já responder ao Cloud Function. O Render.com é uma plataforma que permite hospedar aplicações web de forma simples e barata, com planos a partir de $7 por mês. A ideia é criar uma camada intermediária entre o Cloud Function e o ChatGPT, que recebe a pergunta do Cloud Function e envia uma resposta imediata dizendo que a resposta está sendo gerada. Em seguida, a aplicação em Flask cria uma thread para enviar a pergunta para a API do ChatGPT e assim que obtiver a resposta, atualize a pergunta no Firestore.
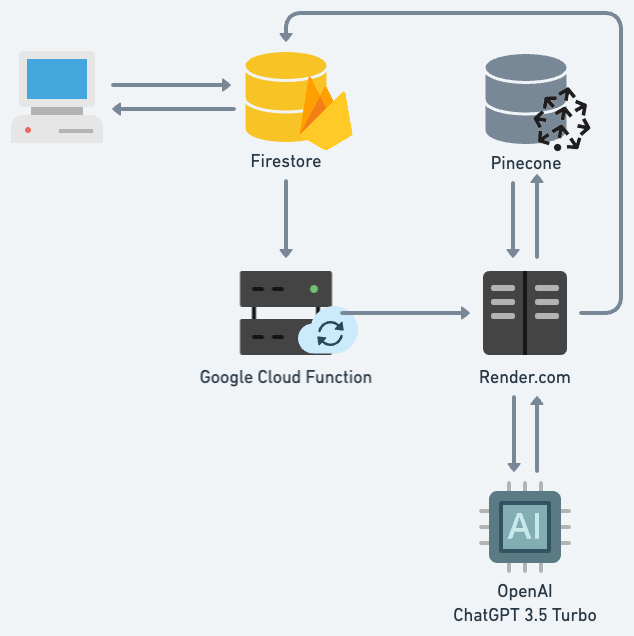
Havia pensado em descrever o código fonte do projeto nesse post. Mas acho que por hora, vale a reflexão sobre a infra aplicada. Posteriormente estarei estarei criando novos post para detalhar mais sobre o projeto em NodeJS inserido no Google Cloud Function e o projeto em Python (Flask) hospedado no Render.com.
A aplicação web responsável por inserir e consultar as perguntas no Firestore ainda está em fase de desenvolvimento. Pretendo publicá-la em breve também.