3 projetos de ciência de dados
Tradução do artigo https://medium.com/pipeline-a-data-engineering-resource/3-data-science-projects-that-got-me-12-interviews-and-1-that-got-me-in-trouble-f376682b4e21 de https://medium.com/@zachl-quinn

Logotipo de grafite Big Trouble. Foto de Nikhil Mitra no Unsplash
Analisando meus projetos de portfólio de ciência de dados
Como muitos graduados, não tive um emprego definido depois de obter meu mestrado em ciência de dados; a razão é porque eu não me inscrevi em lugar nenhum.
Por três meses.
Eu me formei na primavera, mas não comecei minha busca de emprego, a sério, até o verão.
O medo ou a previsão me levaram a acreditar que não estava pronto, e essa emoção me levou a investir as horas em que não trabalhava por hora em um hotel local na elaboração de um portfólio de ciência de dados desejável e comercializável.
Quando recebo comentários e mensagens do LinkedIn com perguntas relacionadas à invasão do setor de dados, minha primeira dica é sempre criar um portfólio hospedado no GitHub que você possa usar como um cartão de visita profissional.
Pontos de bônus se você criar uma documentação atraente ou compartilhar esse conteúdo em uma plataforma como Medium ou LinkedIn para se conectar com possíveis gerentes de contratação.
Embora eu tenha escrito sobre a importância de ter um projeto paralelo, mesmo como um profissional ativo, e compartilhado minhas dicas de comunicação para apresentar projetos de dados, percebi que nunca compartilhei o conteúdo do meu próprio portfólio.
Minha esperança é que, para aqueles que estão se perguntando por onde começar quando se trata de exibir seu trabalho, você verá exemplos reais de quais tipos de projetos chamam a atenção de um recrutador ou entrevistador e por quê.
Antes de compartilhar meu trabalho e processo, devo reconhecer que, embora não tivesse formação formal em tecnologia, tinha as seguintes características que os recrutadores e gerentes consideravam desejáveis (com base no feedback, não no meu egoísmo, juro):
- Um mestrado em ciência de dados
- Conhecimento de domínio (eu propositalmente me inscrevi para cargos nas indústrias de mídia, educação e hotelaria, todas nas quais já trabalhei antes)
- Experiência em desenvolvimento Python/SQL/BI (trabalho de curso, projetos pessoais)
- Habilidades de comunicação (uma grande vantagem, mesmo para engenheiros ou desenvolvedores juniores)
Nota: Desnecessário dizer que seus resultados podem variar.
Projeto 1: painel de análise de dados do curso da Udemy
Resumo: um painel estático que combinou dados de pesquisa do Google e um conjunto de dados do Kaggle para obter informações sobre a frequência do curso e a demanda de conteúdo na plataforma de hospedagem de cursos da Udemy.
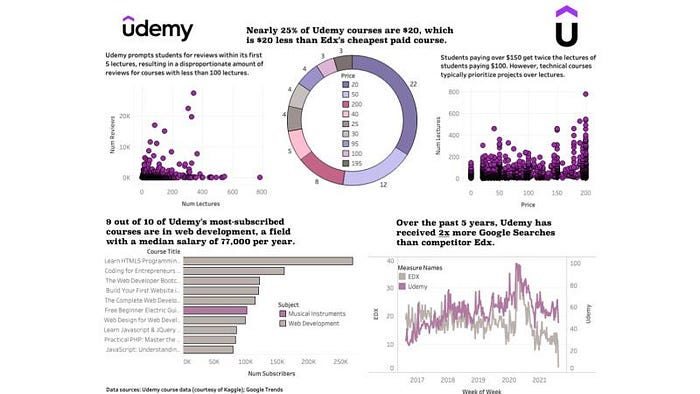
Painel da Udemy pelo autor.
Tecnologia usada:
- SQL
- Tableau
- Python
Conjuntos de dados:
- Conjunto de dados Udemy do Kaggle
- Dados do Google Trends
Principais insights compartilhados:
- Quase um quarto dos cursos da Udemy custam menos de US 20, o que é US 20 a menos que o preço médio do concorrente Edx
- Nos últimos 5 anos, a Udemy recebeu quase o dobro do tráfego de pesquisa do Edx
- 9 dos 10 cursos mais inscritos da Udemy estão em desenvolvimento web
Por que este projeto funciona:
- Relevância do domínio (eu estava me candidatando a uma empresa de educação)
- Práticas recomendadas de visualização de dados demonstradas
- Demonstrou capacidade de conduzir análises competitivas
Projeto 2: A K-Word
Resumo: Após anos de manchetes envolvendo vários 'Karens', decidi investigar as tendências relacionadas à popularidade do nome 'Karen' nos últimos 100 anos e criar visualizações para transformar em uma história baseada em dados.
Tecnologia usada:
- Python
- BigQuery (banco de dados)
- BigQuery (SQL)
Conjuntos de dados:
- Dados do nome do bebê da Previdência Social (BigQuery)
- tendências do Google
Principais insights compartilhados:
- Karen atingiu seu pico em 1957, com uma média de 725 Karens nascidas
- Karen tem uma correlação positiva com as pesquisas por 'racista', 'desagradável' e 'gerente' e uma correlação negativa com as pesquisas por 'bondade'
- Espanha, Iraque e Irã são os países não americanos que mais pesquisaram o insulto 'Karen'
Por que este projeto funciona:
- Novidade
- fluxo narrativo
- Uso de várias fontes de dados
- Visualização clara
Projeto 3: Previsão de rotatividade em inscrições massivas em cursos online abertos
Resumo: Usando regressão logística multivariável, criei 4 modelos para determinar a probabilidade de rotatividade de alunos do MOOC, um grupo conhecido por sua bem documentada falta de compromisso com produtos educacionais .
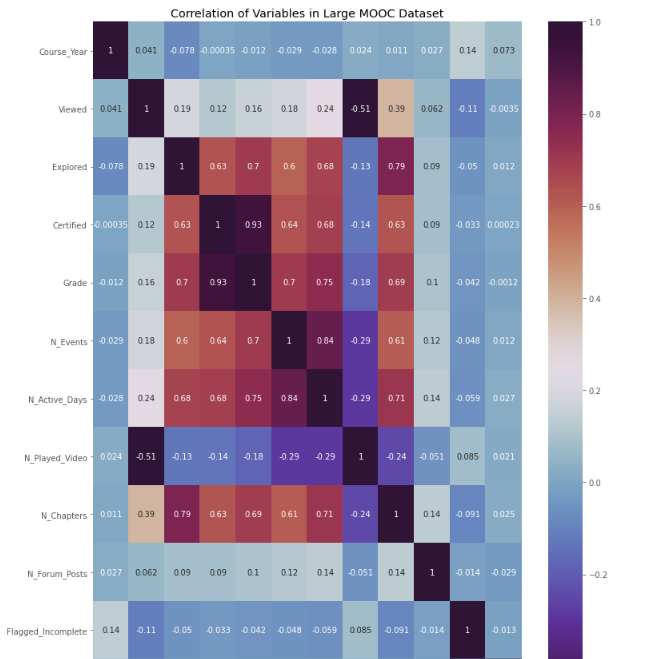
Captura de tela do portfólio do GitHub. Projeto de ciência de dados do autor.
Tecnologia usada:
- Python
- GitHub
Conjuntos de dados:
- Dados Edx (Kaggle)
Principais insights compartilhados:
- Apesar de uma precisão de 90%, a precisão do modelo foi consideravelmente menor (alta de 60%)
- Os melhores preditores de probabilidade de rotatividade incluíram: porcentagem do curso concluído, porcentagem do curso auditado e se o indivíduo possui ou não um diploma de bacharel
- A redução de recursos criou um modelo mais preciso, com métricas de exatidão e precisão girando em torno de 95%
Por que este projeto funciona:
- Aborda um problema de negócios generalizado: churn
- Demonstra proficiência na construção de modelos de ML
- Mostra capacidade de interpretar e apresentar os resultados do modelo
E o projeto que me colocou em apuros…
Tragedy Porn
Sinopse: Em 2018, 5 estrelas de filmes adultos morreram em 3 meses . Embora a maioria das mortes não tenha sido notificada, o suicídio da estrela pornô August Ames, 23 anos, trouxe atenção renovada para uma indústria que experimentou um aumento no número de artistas morrendo antes dos 30 anos devido a suicídio, overdose e violência.
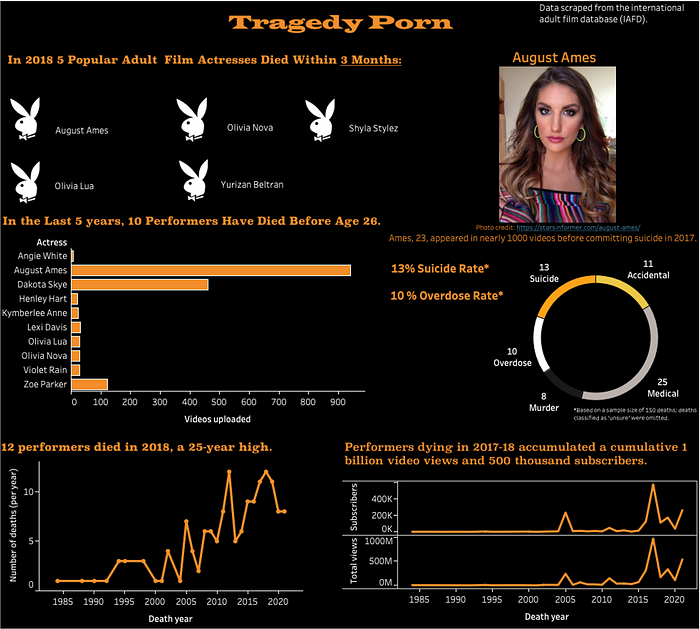
O controverso painel. Dados, visualização e redação do autor.
Tecnologia usada:
- Python
- SQL (SQLLite)
- Tableau
Conjuntos de dados:
- Conjunto de dados personalizado criado pela combinação de dados extraídos da Wikipedia com dados do Kaggle
Principais insights compartilhados:
- Em 2018, 5 atrizes adultas populares morreram com 3 meses de diferença
- Nos últimos 5 anos, 10 artistas morreram antes dos 26 anos
- No total, 12 artistas morreram em 2018, marcando uma alta de 25 anos
Por que este projeto funciona:
- Demonstrou capacidade de criar um conjunto de dados agregado e personalizado (uma habilidade super importante para qualquer trabalho de dados)
- Dados em destaque extraídos da web (uma habilidade muito comercializável)
- Conhecimento exibido das melhores práticas de visualização
- Conta uma história de dados clara e fácil de seguir que envolve o público
Por que isso me colocou em apuros
(Até agora, você provavelmente pode adivinhar)
Apresentei este projeto durante uma entrevista de painel com analistas de dados sênior.
No momento, eles se envolveram e fizeram perguntas sobre como eu reuni, manipulei e exibi meus dados.
Ao que tudo indica, a entrevista correu bem.
Então o recrutador ligou.
Enquanto ela estava feliz em me informar que eu estava avançando para a próxima rodada de entrevistas, ela sugeriu que talvez eu não apresentasse um painel chamado 'Tragedy Porn' aos executivos da empresa na rodada final de entrevistas.
Ela compartilhou que meus entrevistadores sugeriram que, embora a análise fosse sólida, o conteúdo era um pouco controverso (para dizer o mínimo).
Venho do mundo do jornalismo e da mídia, onde pouquíssimos tópicos estão fora de questão, então essa foi uma experiência de aprendizado para mim.
No final, recebi e recusei uma oferta da empresa.
No geral, foi uma ótima experiência com uma lição valiosa para qualquer candidato: conheça seu público e direcione seu conteúdo de acordo.
Recapitulando
Os portfólios de ciência de dados não devem ser adquiridos ou montados levianamente.
Recrutadores, entrevistadores e seus futuros chefes podem absolutamente distinguir entre um repositório de código combinado e um portfólio verdadeiro e bem aprimorado.
Embora seu objetivo não seja replicar o trabalho que compartilhei aqui, certamente há lições a serem aprendidas:
- Certifique-se de que seus projetos escolhidos se concentrem na análise ou tentativa de resolver problemas reais de negócios (pontos de bônus se eles incluírem problemas que sua organização-alvo enfrenta).
- Você provavelmente estará trabalhando nesses projetos por muitas horas não remuneradas. Escolha tópicos e dados que lhe interessam.
- Interpretar e apresentar resultados é uma habilidade negligenciada, mas altamente valiosa. Aprenda a apresentar com confiança e responder a perguntas de acompanhamento.
- Faça sua lição de casa e tente usar uma tecnologia que espelhe o que sua organização-alvo usa. Muitas descrições de trabalho que encontrei apresentavam necessidades pesadas de Python e SQL, daí o foco.
- Conheça seu público e escolha os tópicos de acordo.
Esperançosamente, se você está procurando entrar neste campo, você é apaixonado por dados (ou pelo menos interessado na medida em que você pode fazer o trabalho sem ficar muito entediado).
Além de compartilhar seu portfólio, não tenha medo de compartilhar a história por trás do seu processo com seus entrevistadores.
Os gerentes querem candidatos que sejam apaixonados por dados e resolvam problemas de negócios. Mostre a eles evidências de que essas descrições se aplicam a você.