[TabNews] Novo ranqueamento, otimizações e mais 🚀
Fala Turma do TabNews, muita coisa aconteceu desde a última publicação de melhorias, principalmente otimizações de consultas, mas elas ocorreram em diferentes PRs, então vamos deixar uma visão geral, e mais detalhes podem ser conferidos nos Pull Requests.
Otimizações nas consultas ao banco de dados
Foram implementadas várias otimizações em diferentes PRs. A seguir, destacamos as principais melhorias presentes nos PRs #1400, #1402, #1403, #1410, #1419 e #1421:
-
A função
findChildrenTreefoi refatorada e renomeada parafindTree, pois passou a permitir retornar (opcionalmente) tanto o conteúdo pai como os filhos em uma mesma consulta ao banco. -
Na mesma consulta também é possível buscar o conteúdo diretamente pelo
owner_username, onde antes a gente precisava buscar primeiro oowner_idem uma consulta separada. -
Enquanto ainda estávamos utilizando consultas recursivas para buscar conteúdos root e para buscar (ou apenas contar) os filhos de um conteúdo, passamos a eliminar uma etapa da recursão sempre que possível.
-
Foram invertidas as consultas para montar a página que lista conteúdos de um usuário. Agora buscamos primeiro o usuário e depois os conteúdos. Antes a consulta pelos dados do usuário ocorria após a consulta dos conteúdos, e os conteúdos eram buscados pelo
owner_username, o que é menos performático do que buscar diretamente peloowner_id, que é um campo presente emcontents, e que podemos usar ao buscar os dados do usuário primeiro. -
Foi adotada a estratégia de armazenar o caminho materializado dos conteúdos para facilitar a obtenção da árvore de comentários sem precisar de consultas recursivas.
-
Para isso, primeiro foi adicionado uma coluna
pathna tabelacontentsque armazena oidde todos os conteúdos que estão acima do item na árvore. -
Foi criado um índice GIN nessa coluna
path. -
Passamos a utilizar
pathno lugar da maioria das consultas recursivas. Por exemplo, para buscar todos os filhos de um conteúdo, passamos a filtrar porWHERE children.path @> ARRAY[contents.id]. -
Foi removida a função
findRootContente passamos a buscar o conteúdo root diretamente pelo primeiroidempath. -
Agora só buscamos o conteúdo root se ele existir, o que é verificado pelo
path, eliminando consultas desnecessárias, por exemplo, ao criar notificações e ao montar a página de conteúdos.
Algumas outras modificações foram realizadas nos PRs citados, onde as principais são:
-
Ao classificar os comentários, ordenar itens apenas entre os irmãos (conteúdos abaixo do mesmo pai). Antes ocorria uma ordenação geral antes da estrutura da árvore ser montada.
-
Foi reformulada a equação de cálculo de score de comentários utilizada para ordenação. Estamos utilizando uma equação mais simples de ser computada e sem o bug de conteúdos negativados que existia na versão anterior.
-
Mudamos a validação de
owner_usernamepara ser igual à deusername, para que as novas consultas possam mostrar corretamente páginas 404 ao tentar acessar conteúdo de usuário inválido ou inexistente.
As implementações foram realizadas por mim, mas agradeço toda a ajuda do @filipedeschamps e do @FabricioFFC para chegarmos na solução utilizando caminho materializado. Também agradeço ao @GHCMelo por ter reportado rapidamente um bug introduzido em uma das alterações.
Nos PRs existem algumas métricas específicas das melhorias, mas vou deixar um gráfico capaz de mostrar um impacto geral das mudanças, que é o tempo de execução das funções lambdas, ou seja, quanto tempo nosso backend levou processando requisições ao longo de cada dia, onde boa parte desse tempo era aguardando o processamento das consultas no banco de dados.
Independentemente dos números absolutos, notem que a quantidade de invocações permaneceu mais ou menos estável ao longo do mês, mas o tempo total de execução foi bastante reduzido nas duas etapas de implantação das otimizações.
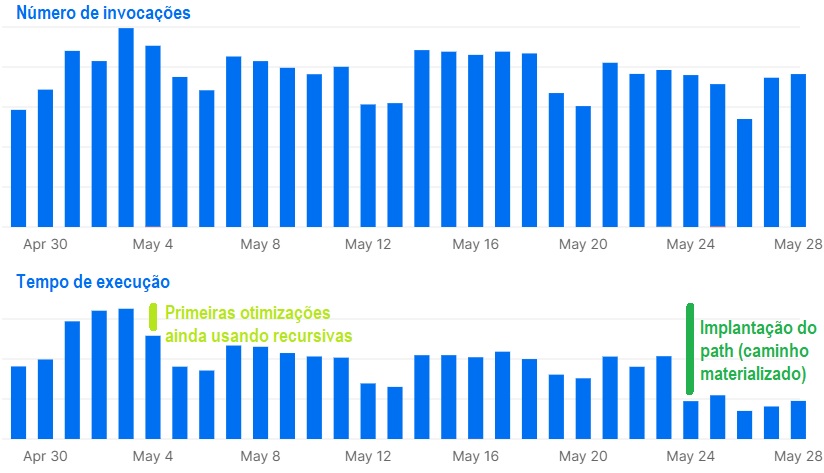
Gráfico 1 - Diminuição no tempo de execução das funções lambdas com as otimizações realizadas.
Agora boa parte do tempo de execução das lambdas é utilizado para a validação dos dados retornados do banco, principalmente quando é grande a quantidade de comentários em uma publicação. Então a validação é uma ótima opção para quem quiser investigar o que podemos otimizar. 👍
Botão de nova publicação no header (+)
Era uma solicitação recorrente, então o @victorhcb abriu o PR #1349 que adicionou o botão de publicação na versão desktop.
Configuração do cache
No #1406 foram criadas funções para definição de cache dos endpoints/métodos da API. Além da padronização da configuração de cache, com elas seremos alertados durante o desenvolvimento se o cache for definido mais de uma vez (com valores diferentes) em uma mesma requisição.
Regra ESLint no-unused-vars
Para uma melhor organização do código, foi habilitada a regra no-unused-vars, que visa eliminar variáveis, funções e parâmetros de função não utilizados.
A implementação foi iniciada pelo @omariosouto lá atrás no PR #404 e foi continuada mais recentemente pelo @issdomingoss no PR #1337. Eu apenas fiz os ajustes finais no PR #1410.
Melhoria nas thumbnails
A geração das imagens de compartilhamento de publicações em redes sociais continha um bug que podia deixar o texto sobreposto à logo, isso dependendo da largura dos caracteres presentes no texto.
O @OtavioVB iniciou uma correção com o PR #559, mas na mesma época a Vercel estava lançando a biblioteca @vercel/og, que parecia que ia nos ajudar a resolver o problema, mas que acabou não ajudando, pois nosso banco de dados não pode ser acessado diretamente da Edge da Vercel.
Com essa restrição em mente, o @ErickCReis começou a realizar testes utilizando a biblioteca satori, também da Vercel, e que está por trás da og. E com isso ele chegou recentemente na versão final com o PR #1425.
A nova versão não tem mudanças visuais significativas, mas corrigiu o bug que existia:
Refatoração da função can em authorization
A função can verifica se um usuário está autorizado a realizar determinada ação no TabNews e retorna um booleano. Ela funcionava muito bem, mas era difícil de ser lida e entendida pelos desenvolvedores, tanto que houveram algumas tentativas de refatoração, mas que não conseguiram diminuir significativamente a complexidade.
Até que o @JoandersonPaiva fez uma proposta diferente das anteriores, utilizando early return, o que deixou mais visível qual seria o retorno da função em cada caso, e isso deve facilitar para quem estiver realizando contribuições que envolvam de alguma maneira essa função.
Os detalhes estão no PR #1427.
Nova classificação de conteúdos relevantes
A implementação da estratégia de caminho materializado (path) agilizou a consulta da árvore de comentários, possibilitando o uso dessa informação na classificação de conteúdos relevantes. Então agora são computados quantos usuários diferentes interagiram com as publicações e essa informação é utilizada junto com o saldo de TabCoins e o tempo de publicação para classificar os relevantes.
A mudança foi realizada por mim e os detalhes estão no PR #1426.
Lembrando que a qualificação de conteúdos ainda é a maneira que mais impacta a classificação, então é muito importante que continuem aproveitando toda oportunidade que tiverem de transformar seus TabCoins em TabCash, seja para ajudar a melhorar o ranqueamento 🚀, seja porque TabCash é a moeda que será muito importante quando for lançado o Revenue Share. 🤑
Conclusão
Tem muita coisa legal e impactante pra melhorar no TabNews, e que exigem diferentes níveis de conhecimento, então dá para contribuir com coisas simples, porém úteis, quando estiverem precisando de dopamina, mas também dá para evoluir muito com a gente ao interagir nas contribuições mais difíceis.
Valeu Turma! 💪