Não use o app Lensa! Crie suas próprias imagens com I.A. no seu PC ou Google Colab com Stable Diffusion!
Quem deu uma passada por uma rede social nas últimas semanas, se deparou com as imagens de perfil que parecem ter sido feitas por artistas muito talentosos.
É simplesmente impressionante o nível das imagens geradas por Inteligência Artificial!

Acontece que o Lensa, app responsável pela façanha, tem gerado uma certa polêmica, por ter termos de uso um tanto quanto questionáveis em relação aos direitos sobre dados pessoais dos usuários.
Basta você fazer algumas fotos virando o rosto em algumas direções e vender a alma pro capiroto para conseguir gerar as imagens. Brincadeiras a parte, se liga na tradução de parte dos termos de uso do app (feita pelo Canaltech):
"Lensa pode permitir que você faça upload, edite, crie, armazene e compartilhe conteúdo, incluindo fotos e vídeos. (...) Exceto pela licença garantida abaixo, você tem todos os direitos pelo seu conteúdo de usuário (...).
Você garante a nós licença perpétua, irrevogável, não-exclusiva, livre de royalties, mundial, totalmente paga, transferível e licenciável para usar, reproduzir, modificar, adaptar, traduzir, criar obras derivativas e transferir seu conteúdo de usuário, sem qualquer compensação adicional ou consentimento explícito (...). A licença é para propósitos limitados de operação, desenvolvimento, fornecimento e melhorias no Lensa e pesquisa, desenvolvimento e melhoria de produtos existentes ou novos, incluindo mas não limitado ao Lensa (...)."
Stable Diffusion
De acordo com o site https://stablediffusionweb.com/, em tradução livre:
Stable Diffusion é um modelo latente de difusão de texto para imagem capaz de gerar imagens fotorrealistas a partir de qualquer entrada de texto. Ou seja, você digita em um prompt o que quer ver, ajusta alguns poucos parâmetros, e a I.A. gera as imagens pra você baseado no que foi escrito.
Em uma analogia muito bacana, o Niko (Corridor Digital) disse que o comportamento da I.A. é similar a uma pessoa tentando ver desenhos em nuvens, gerando uma imagem cada vez mais definida a cada passada na imagem anterior.
Partindo de um ruído aleatório, a cada passada vai se obtendo mais definição da imagem gerada (similar ao GAN em alguns aspectos).

O Stable Diffusion usa Textual Inversion para o treinamento dos modelos. De acordo com o site huggingface.co:
A inversão textual é uma técnica para capturar novos conceitos a partir de um pequeno número de imagens de exemplo de uma forma que pode ser usada posteriormente para controlar pipelines de texto para imagem. Ele faz isso aprendendo novas "palavras" no espaço de incorporação do codificador de texto do pipeline. Essas palavras especiais podem ser usadas em prompts de texto para obter um controle muito refinado das imagens resultantes.
- Ou seja, no processo de treinamento, a partir das imagens iniciais ele gera textos descritivos e posteriormente faz a inversão e usa estes textos pra ajudar a criar as novas imagens.
Eu já tinha visto o uso desta técnica de geração de imagens em alguns lugares, como o canal Corridor Crew, Midjourney e Dall-E2.
Olha só estas imagens que misturam Cyberpunk com Egito antigo, geradas com o Midjourney e publicadas pelo usuário Everton Lisboa no UNHIDE School Group no Facebook:



Visto tudo isso, decidi então pesquisar um pouco mais a fundo sobre o assunto pra descobrir o quão viável treinar um modelo com meu rosto e gerar imagens pelo meu PC de casa.
E o timming foi perfeito, pois o assunto está muito quente e a comunidade opensource tá entregando soluções cada vez mais otimizadas, com evolução exponencial a cada semana. Tá uma loucura o nível que já chegou!!
E consegui chegar em um resultado que me impressionou!
Para referência, este aqui sou eu:

Olha aí algumas das minhas imagens geradas:







Tá bom. Me explica melhor como funciona isso..
Este vídeo feito pelo Leon do canal Coisa de Nerd, explica de forma muito didática, sem entrar na parte técnica, como funciona a coisa toda:

Um pouco mais mão na massa
Quero ver isso funcionando agora!!
Existem muuuitas alternativas pra gerar estas imagens diretamente on-line e sem custo (com limitações). Sendo o canal de Discord do Midjourney o que considero ter os resultados mais impressionantes, porém com uso gratuito bem limitado.
Porém, o Playground AI te permite gerar até 1.000 imagens por dia gratuitamente e sem restrição pra uso pessoal e comercial.
Além de contar com diversos exemplos de prompts pra você se inspirar!

Show me the code!!!
Existem alguns repositórios com o código fonte incluindo uma interface web que você pode utilizar para gerar imagens com os prompts e até mesmo treinar seus próprios modelos.
Gostei muito de 2!
-
O mais completo e relativamente amigável: Automatic 1111

-
O mais amigável (porém ainda não tem treinamento pela interface): Invoke AI
Se você seguir estes vídeos, vai conseguir instalar na sua máquina sem problemas.
Agumas dicas e observações minhas:
Sobre a instalação (Automatic 1111):
- Caso não tenha uma placa de vídeo, dá pra rodar diretamente do Google Colab!!! Encontrei um vídeo em português que afirma explicar o processo passo a passo (mas não assisti a este vídeo especificamente):
- Pra rodar diretamente no seu PC, você vai precisar de uma placa de vídeo razoável, preferencialmente NVIDIA, das séries 20, 30 ou 40, com pelo menos uns 8GB de memória VRAM.
- Um pouco na contramão dos tutoriais, eu preferi instalar e manter no WSL2 do Windows com Linux Ubuntu, ao invés de diretamente no Windows. O que funciona perfeitamente bem.
- Cheguei a instalar no Windows 11 apenas pra teste, mas removi depois de constatar que também funciona.
- Usei o o gerenciador de versões PyEnv pra instalar o Python isoladinho na versão 3.10.6 sem bagunçar nada na minha máquina.
- Para otimizar vários recursos de Transformers pode-se utilizar a biblioteca xFormers criada pelo Facebook, mas não precisa instalar separadamente! Basta dar o comando pra iniciar a interface web incluindo o argumento: --formers
- No Windows: webui.bat --formers
- No Linux: webui.sh --formers
- Para não ter q fazer isso toda vez, inclua isto no arquivo webui-user.sh (ou .bat se Windows):
export COMMANDLINE_ARGS="--xformers"- Aproveite pra incluir mais um comando ao final deste arquivo e manter o código fonte sempre atualizado:
git pull

Sobre o treinamento das minhas próprias imagens
- Não use fotos demais nem de menos. O ideal é fazer 20 fotos em varias poses:
- 3 fotos de corpo inteiro
- 5 fotos do cotovelo pra cima
- 12 fotos do rosto
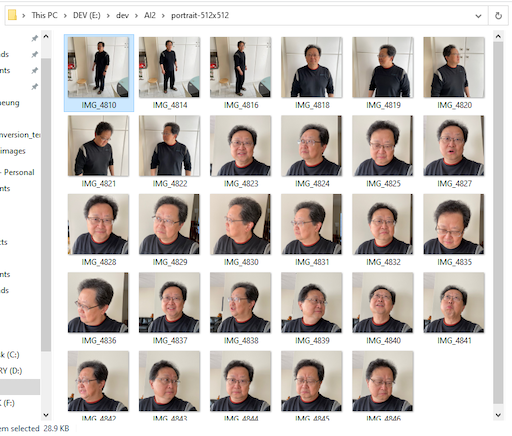
- Crie uma conta no https://huggingface.co/ para baixar os modelos de Stable Diffusion (arquivos .ckpt) a serem utilizados. Os da versão 2.X precisam também
- Stable Diffusion 1.4: Modelo que usei como base pro treinamento das minhas fotos.
- Stable Diffusion 1.5: Uma versão mais refinada do 1.4 (recomendo esta versão).
- Stable Diffusion 2.0: Com melhorias em alguns aspectos e muita piora em outros, teve bastante reclamações da comunidade.
- Stable Diffusion 2.1: Teoricamente um versão melhorada do 2.0, retornando algumas sas principais vantagens das versões 1.X (ainda não testei).
- Testei 2 métodos de treinamento:
- Hypernetwork: Ele adiciona as informações treinadas ao modelo atual de forma não invasiva, funcionado como uma camada a mais que você habilita ou desabilita a qualquer momento (Este processo é feito na aba Settings na interface do Automatic 1111).
- É necessário treinar algumas vezes, refinando com base nos seus resultados preferidos.
- Este é o melhor guia que achei sobre treinamento com a técnica de Hypernetwork (apesar de eu ter preferido usar Dreambooth, muita coisa daqui é aproveitável):

- Dreambooth: Uma interface de treinamento mais facilitada e automatizada. Gera automaticamente os arquivos de Checkpoint (.ckpt) que são o modelo que vc seleciona no topo da interface.
- Este é o melhor guia que achei sobre treinamento com a técnica de Dreambooth:

- No repositório do Joe Penna (Lembra do MysteryGuitarMan? O Brasileiro que fazia uns vídeos muito loucos e fez sucesso mundial... É ele mesmo!!) tem umas informações bem legais sobre o Dreambooth: https://github.com/JoePenna/Dreambooth-Stable-Diffusion
- Imagens de regularização de classes: Quando você treina um modelo, você pode (e deve) definir classes para a imagem treinada, por exemplo: homem, mulher, pessoa, avião, cachorro, gato. Para que o seu treinamento seja mais efetivo, o uso de imagens de referência de classe (regularização) é essencial.
O Dreambooth pode gerar automaticamente estas imagens (cerca de 200), ou você pode baixar para economizar tempo e processamento (lembre-se de usar apenas umas 200 imagens):
https://github.com/JoePenna/Stable-Diffusion-Regularization-Images - Não tente treinar modelos usando somente a CPU, você só vai se frustrar. Se não tiver GPU, use o Google Colab.
- Hypernetwork: Ele adiciona as informações treinadas ao modelo atual de forma não invasiva, funcionado como uma camada a mais que você habilita ou desabilita a qualquer momento (Este processo é feito na aba Settings na interface do Automatic 1111).
Sobre os parâmetros e prompts
- Além dos prompts, os principais parâmetros para se observar são:
- Sampling Steps: A quantidade de passadas feita na geração da imagem, quanto mais, mais pesado de processar. Esse parâmetro pode mudar bastante a imagem gerada.
- GFC Scale: Quanto maior esse número, mais literal a I.A. vai ser em relação ao prompt
- Seed: Número de base para o random do ruído inicial de geração da imagem. Se você mantiver o prompt e usar o mesmo seed de uma imagem já gerada, mudando um pouco os parâmetros anteriores (Sampling Steps e GFC Scale), vai conseguir refinar melhor uma imagem que te agradou.
- Negative Prompts: São coisas que você não quer que sejam geradas na imagem. Eu recomendo fortemente usar este recurso para obter melhores resultados, evitando imagens distorcidas, com mutações malucas e outros problemas.
- Negative Prompt para usar na maioria das imagens (peguei daqui):
Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ((((mutated hands and fingers)))), (((out of frame)))
- Para buscar inspirações de prompts, use o https://lexica.art/
- Lembrando que o Playground AI que citei anteriormente também faz muito bem esse papel
Conclusão
Existe um grande debate rolando sobre o assunto. Muita gente está com medo da tecnologia e acredita que vai perder seu emprego. Provavelmente vai mesmo. Mas a gente precisa se adaptar e entender onde nos encaixamos nisso tudo, aprendendo a usar as ferramentas ao nosso favor. É assim toda vez que surge algo inovador no mundo, por exemplo a invenção da máquina de costura: https://www.maquinasuniao.com.br/conheca-a-historia-da-invencao-da-maquina-de-costura/
Ainda tenho muito a aprofundar no assunto e posso ter esquecido de algo no post. Mas caso eu lembre ou aprenda mais alguma coisa, irei complementando aqui. :)
Espero que curtam os resultados!
Como eu disse, precisamos aprender a usar estas coisas ao nosso favor. Mas se isso te assustou, espere pra ver o post que vou fazer sobre o ChatGTP.