Gerenciamento de Servidores para Aplicações de Médio Porte (Amazon Lightsail)
Neste post vou compartilhar com vocês um poucos das decisões tomadas ao longo do crescimento de uma aplicação WEB.
Nascimento da Aplicação
Ao colocar uma aplicação no ar, normalmente nos contentamos em colocarmos o banco de dados e a aplicação rodando no mesmo servidor. Afinal, é extremamente econômico e em muitas aplicações isso é realmente muito funcional.
Mas comecei a encontrar problemas quando o número de usuários foi crescendo e ao abrir o gerenciador de tarefas (Executando o comando top), lá estava o mysql roubando todo o processamento.
Meu OS favorito para servidores web é Ubuntu Server (podem me julgar).
Separando o Banco de Dados MySQL
Junto com os problemas de alta carga da CPU pelo mysql, também comecei a enfrentar problemas severos no servidor (por má configuração de algumas coisas), problemas daqueles que tentamos consertar e só pioramos tudo. E o pior, o servidor não podia parar, porque se trata de uma aplicação médica que funciona 24hr por dia. E agora?
Então percebi que eu precisava isolar totalmente a aplicação, pra que o servidor de aplicação fosse totalmente descartável. Afinal, restaurar um snapshot do servidor é mais rápido doque gastar horas tentando consertar algum problema no OS.
Então fiz a seguinte organização:
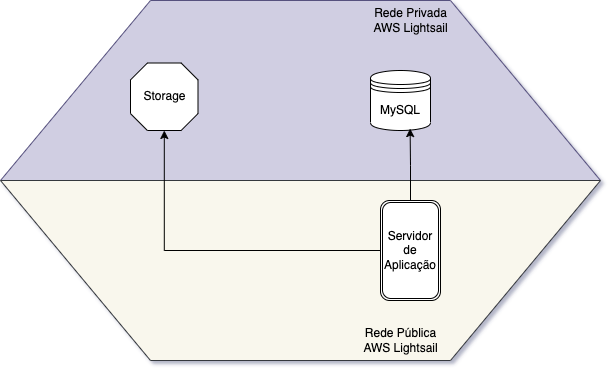
Nesta organização eu criei um container MySQL (15 USD / mês) e um storage 100GB (3 USD / mês), e com isso eu pude reduzir o meu servidor de aplicação para um server basicão de 1vCPU e 1GB de Ram ($5 USD / mês).
E tudo rodou lindamente.
A necessidade do Storage surgiu para que os uploads do usuário não ficassem na aplicação, tornando um possível discarte do servidor de aplicação trabalhosa de ter que migrar esses arquivos.
Ampliando
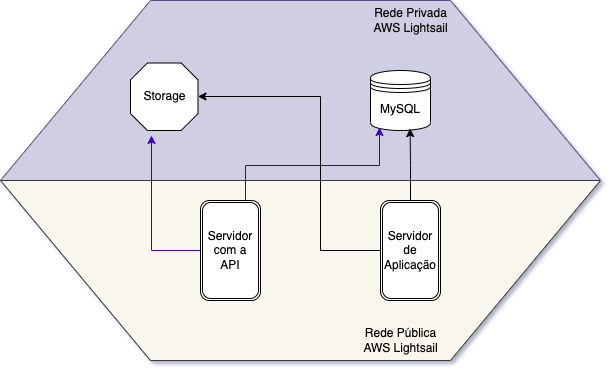
Com o tempo foi necessário uma expansão para novas plataformas (como mobile), na plataforma mobile era necessário ter uma api diferenciada, com recursos diferentes da aplicação web. Então foi criado uma API, que era uma outra aplicação, mas rodava no mesmo servidor da aplicação web.
Daí logo disponibilizamos a API para que aplicações de terceiros pudessem se conectar e então novamente o gargalo da aplicação foi ficando estreito.
Então... veio a segunda remodelagem.
Armazenamento de Dados Estáticos
Com as integrações de terceiros, APIs e etc... foram surgindo demandas que faziam o banco de dados chorar. As gerações de relatórios que necessitavam cruzamento de dados às vezes entre 3 tabelas, e isso estava dando picos de processamento no container MySQL, que atrapalhava a aplicação principal.
Como a maioria dos relatórios gerados, são de consulta a dados passados, e que nunca serão alterados (como por exemplo, a quantidade de atendimentos feitos ao dia), era possível armazenar os dados estaticamente. E assim fizemos:
<?php
$relatorio = "yyyy_mm_dd";
$localPath = __DIR__."/../temp/DADOS_BRUTOS/file_records_$relatorio.json";
$storagePath = "DADOS_BRUTOS/file_records_$relatorio.json";
if(!file_exists($localPath)){ // Se o arquivo não existir no servidor da aplicação
if(MyStorage::has($storagePath)){
/* Se existir no Storage, ele vai baixar para a aplicação */
MyStorage::download($storagePath,$localPath);
}else{
/* Se não existir no Storage, é porque os dados não existem estaticamente, então precisam ser gerados e enviados para o Storage.*/
file_put_contents($localPath,gerarDados($relatorio))
MyStorage::upload($localPath,$storagePath);
}
}else if(!MyStorage::has($storagePath)){ // Agora se o arquivo existir, só vai verificar se ele está tbm no Storage. Se não estiver, vai fazer upload para lá.
MyStorage::upload($localPath,$storagePath);
}
$dados = file_get_contents($localPath); // Leitura dos Dados
header("Content-Type: application/json");
echo $dados; // Exibindo
?>
Este código em Javascript:
import MyStorage from './storage.js'
import Admin from './admin_records.js'
const fs = require('fs');
async function handler(req,res){
const relatorio = req.query.date;
const localPath = "/temp/DADOS_BRUTOS/file_records_"+relatorio+".json";
const storagePath = "DADOS_BRUTOS/file_records_"+relatorio+".json";
if(!fs.existsSync(localPath)){
if(MyStorage.has(storagePath)){
await MyStorage.download(storagePath,localPath);
}else{
fs.writeFileSync(localPath,Admin.gerarDados(relatorio));
await MyStorage.upload(localPath,storagePath);
}
}else if(!MyStorage.has(storagePath)){
await MyStorage.upload(localPath,storagePath);
}
const dados = fs.readFileSync(localPath);
res.writeHead(200, { 'Content-Type': 'application/json'});
res.write(dados);
res.end();
}
Com os códigos à cima, seguindo a lógica, apenas o primeiro usuário à buscar pelo relatorio do dia 04/12/2022 irá esperar o banco de dados calcular os dados e reunir os dados, o próximo à solicitar esse relatório, já irá puxá-lo de um arquivo estático no servidor, com os dados mastigados e tratados.
Desta forma, agora eu posso, à qualquer momento descartar o meu servidor de aplicação e remontar um snapshot absolutamente sem preocupação.
Pra facilitar, mantenho o repositório github conectado ao servidor de aplicação para que as atualizações possam ser aplicadas à uma linha de código de distância.
Bom... espero que esse post possa ajudar vocês de alguma forma, em algum momento.
Tmj \o/