🕷️ Fiz um Web Scraping com Multithreading no Tabnews
Se tem uma técnica que é útil para infinitas aplicações é o Web Scraping e aliado a Mutithreading a coisa fica ainda mais interessante.
Não sabe do que estou falando, vem comigo então que você vai aprender não apenas Web Scraping outras cositas mas ;)
Bora carregar dados online no modo Turbo !
Algumas explicações inicias
O código a seguir utiliza o Tabnews para leitura dos dados apenas como forma de exemplificar a utilização das técnias aplicadas. Obviamente que devido a controles como Cloudflare este e outros websites terão comportamentos diferentes do código. Além disto, em geral, o web scraping em si não é ilegal, mas o uso indevido de informações coletadas por meio de web scraping pode ser ilegal e sujeito a sanções legais. Aprecie com moderação ;)
O que é Web Scraping?
Web scraping é o processo de extrair dados de sites. No mundo de hoje, o web scraping se tornou uma técnica essencial para empresas e organizações coletarem dados valiosos para suas pesquisas e análises. O Node.js é uma plataforma poderosa que permite aos desenvolvedores executar o web scraping de maneira eficiente e escalável.
O que é Web Scraping Multithreaded?
Multithreaded é um termo que se refere à capacidade de um programa ou sistema operacional de executar várias tarefas simultaneamente em diferentes threads ou fluxos de execução. Isso permite que um programa ou sistema opere de maneira mais eficiente, aproveitando ao máximo a capacidade de processamento do hardware disponível. O uso de múltiplas threads também pode melhorar a capacidade de resposta do programa ou sistema, permitindo que várias tarefas sejam executadas em paralelo, em vez de esperar que uma tarefa termine antes de iniciar a próxima.
Scraping + Multithreaded?
O Web Scraping Multithreaded é uma técnica que envolve dividir a tarefa de scraping em várias threads. Cada thread executa uma parte específica do processo de scraping, como baixar páginas da web, analisar HTML ou salvar dados em um banco de dados. Ao usar várias threads, o processo de scraping pode ser executado em paralelo, o que pode melhorar significativamente a velocidade e eficiência da tarefa de scraping.
Por que usar o Web Scraping Multithreaded?
Existem várias razões pelas quais o web scraping multithreaded é benéfico. Em primeiro lugar, pode reduzir significativamente o tempo necessário para coletar grandes quantidades de dados de vários sites. Em segundo lugar, pode melhorar o desempenho do processo de scraping, utilizando os recursos da máquina de forma mais eficiente. Por fim, pode ajudar a evitar possíveis obstáculos, como ser bloqueado por um site devido à sobrecarga de solicitações de um único endereço IP.
Como implementar o Web Scraping Multithreaded no Node.js?
Para implementar o web scraping multithreaded no Node.js, podemos usar uma biblioteca chamada "cluster". A biblioteca cluster permite a criação de processos filho que podem ser executados em paralelo e se comunicar entre si por meio de um espaço de memória compartilhada. Ao criar vários processos filho, podemos distribuir a tarefa de scraping em todos os núcleos disponíveis da CPU.
Assincronicidade
Assincronicidade, ou "asynchronous" em inglês, é uma característica fundamental do JavaScript que permite que o código seja executado sem bloquear a execução do programa. Em outras palavras, o JavaScript é capaz de executar várias tarefas ao mesmo tempo, o que é essencial para lidar com operações que possam levar mais tempo para serem concluídas, como o carregamento de arquivos, requisições HTTP e outras operações de entrada e saída.
Em vez de bloquear a execução do programa enquanto uma tarefa é concluída, o JavaScript permite que outras tarefas sejam executadas enquanto a tarefa assíncrona está em andamento. Isso é feito usando callbacks, Promises ou async/await, que permitem que o código seja executado de forma não sequencial, conforme as tarefas são concluídas.
The Code !
Tá tudo lá no GitHub prontinho para você utilizar. Mas segue um overview.
index.js
const cluster = require("cluster");
const numCPUs = require("os").cpus().length;
const Worker = require("./worker");
// Helpers
const { log } = require("./helpers");
// CONFIGs
const MAX_CPUS = 0; // Max number of CPUs to use
const URL = "https://www.tabnews.com.br"; // Base URL to web scraping
// Global variables
let page = 0; // Page number
let activeWorkers = 0; // Number of active workers
// CPU usage
let numTheads = numCPUs > MAX_CPUS && MAX_CPUS ? MAX_CPUS : numCPUs;
// ----------------------------------------------------------------------------------------------------
// Clusters
if (cluster.isMaster) {
// *** MAIN PROCESS ***
// Create a worker for each CPU
for (let i = 0; i < numTheads; i++) {
forkWorker();
}
// On exit
cluster.on("exit", (worker, code, signal) => {
log(worker.process.pid, { status: `Ended` });
activeWorkers--;
forkWorker();
});
// Fork new worker
function forkWorker() {
if (activeWorkers < numTheads) {
const worker = cluster.fork();
activeWorkers++;
worker.on("online", () => {
log(worker.process.pid, { status: `Started` });
// Page
page++;
// Execute
worker.send({ URL, page }, (error) => {
if (error)
log(worker.process.pid, {
status: `Error sending parameters`,
error,
});
});
});
worker.on("message", (msg) => {
if (msg.message === "Worker done") {
log(worker.process.pid, { status: `Worker done` });
activeWorkers--;
forkWorker();
}
});
worker.on("error", (err) => {
log(worker.process.pid, { status: `Error:`, err });
});
worker.on("exit", (code, signal) => {
log(worker.process.pid, { status: `Exited`, code, signal });
activeWorkers--;
forkWorker();
});
}
}
} else {
// *** WORKER PROCESS ***
process.on("message", async (params) => {
log(process.pid, { status: `Received parameters :`, params });
// Run worker engine
await Worker(process.pid, params);
process.send({ message: "Worker done" });
});
}
worker.js
const puppeteer = require("puppeteer");
const fs = require("fs");
// Helpers
const { log } = require("./helpers");
async function Worker(workerPID, params) {
log(workerPID, { status: `Running with params`, params });
// Constants
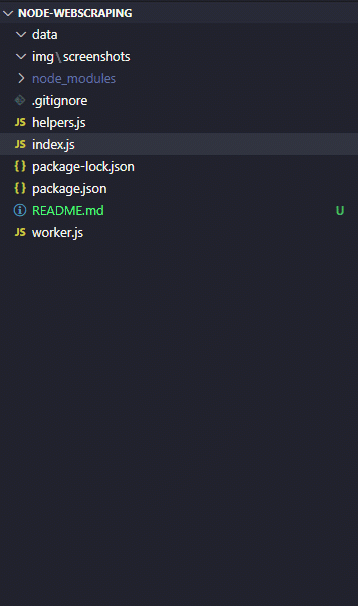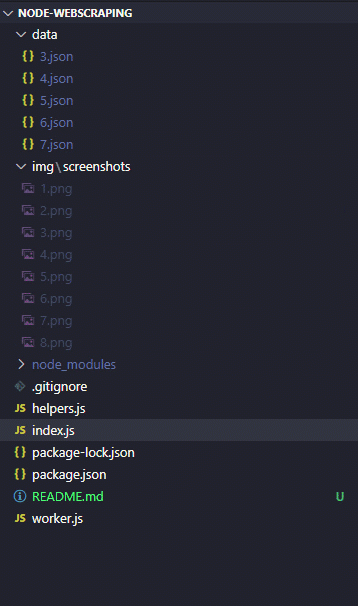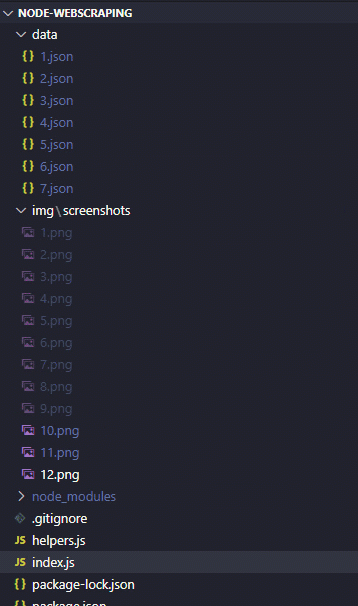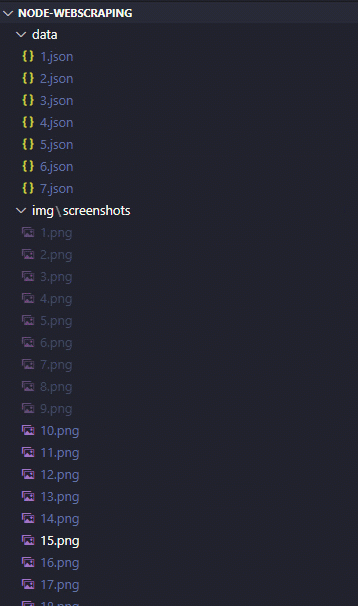
// Screenshots path
const PATH_SS = "img/screenshots/";
// Data path
const PATH_DATA = "data/";
// Element load target
const EL_LOAD = "#header";
// Element target
const EL = "article";
// Configs
const { URL, page: numPage } = params;
// Check required params
if (!URL) return log(workerPID, { status: `Missing required params` });
// Base URL for the search results page
const loadURL = URL + "/recentes/pagina/" + (numPage || 1);
// Launch browser
const browser = await puppeteer.launch();
log(workerPID, { status: `Browser opened >`, loadURL });
// Open URL
const page = await browser.newPage();
await page.goto(loadURL);
// Wait for page to load
await page.waitForSelector(EL_LOAD);
log(workerPID, { status: `Page loaded` });
// Escape screenshot page to debug
await page.screenshot({ path: PATH_SS + numPage +'.png' });
// Extract search results
const elements = await page.$$(EL);
// Data array
const data = [];
// Reading the data
for (const element of elements) {
// Find A element inside article
const a = await element.$("a");
// Skip if not found
if (!a) continue;
// Get A data
const route = await a.evaluate((node) => node.getAttribute("href"));
const title = await a.evaluate((node) => node.textContent);
// Add to data array
data.push({
title,
url: URL + route,
});
}
// Return search results
const jsonRet = {
data,
page: numPage,
total: data.length || 0,
updated: new Date(),
};
// Close browser
await browser.close();
// Save Json file
try{
// Save file
const file = PATH_DATA + numPage + ".json";
log(workerPID, { file });
fs.writeFileSync( file, JSON.stringify(jsonRet));
// File saved
log(workerPID, { status: `Json file saved` });
} catch (err) {
// Error saving file
log(workerPID, { status: `Error saving file`, err });
}
// End process
try {
process.exit(0);
} catch (e) {
// Cant end process for now
}
}
module.exports = Worker;
Executando o código
Neste exemplo de código, usamos tabnews.com.br como target.
O objetivo é gerar arquivos JSON listando o título e URL dos artigos de cada página.
Nosso código irá:
- Iniciar o processo principal e bifurcar cada processo de cluster com base nos CPUs disponíveis;
- Aplicar o mecanismo de Web Scraping a cada cluster;
- Ler a página, gerar a captura de tela e dividir o conteúdo na lista de artigos;
- Salvar um arquivo .json com o título e URL do artigo;
- Finalizar o processo e reiniciar outro;
Com estes dados isolados e de fácil manipulação fica fácil utilizar para diversas finalidades.
Vamos manter contato
Espero que seja útil e que você goste!
Bora nos conectar no Linkedin e me siga por lá para ver o que vem por ai ;)
Até ! :)