Desvendando a GenAI - Parte 4 - O que é um prompt? O que são tokens? Como interagir com uma LLM? Quanto custa?
A inteligência artificial (IA) generativa tem se tornado cada vez mais presente no dia a dia de empresas e profissionais, especialmente através dos Large Language Models (LLMs) — modelos avançados que são capazes de gerar textos, realizar traduções, responder perguntas, e muito mais. A seguir exploraremos as LLMs como serviço, os conceitos de prompts e tokens, e como a precificação desses modelos funciona, especialmente em relação ao uso de prompts e tokens.
O Que é LLM como Serviço?
LLM como serviço permite o acesso a modelos de linguagem avançados sem a necessidade de construir ou treinar modelos do zero. Esse tipo de serviço é oferecido por empresas como OpenAI, Google, e Anthropic.

As vantagens são evidentes: você tem acesso a um modelo poderoso, atualizado e treinado com vastos conjuntos de dados, pagando apenas pelo uso. Isso facilita a adoção de IA para empresas e profissionais que precisam de soluções escaláveis para geração de texto e outras tarefas de processamento de linguagem natural.
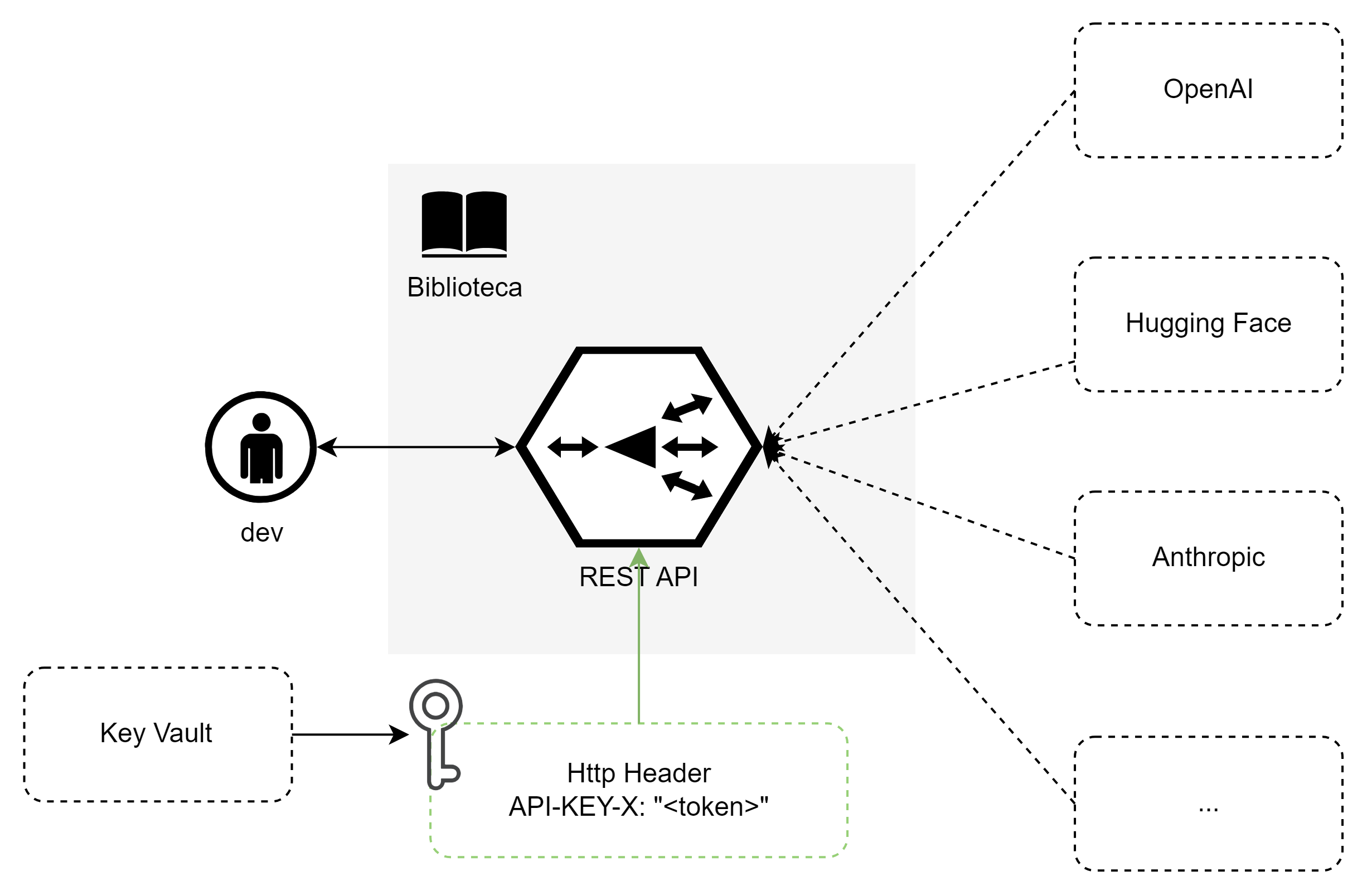
Atualmente os principais serviços oferecem bibliotecas para as principais linguagens. Assim você não precisa acessar a REST API diretamente, essas bibliotecas fazem isso pra você!
O Que São Prompts?
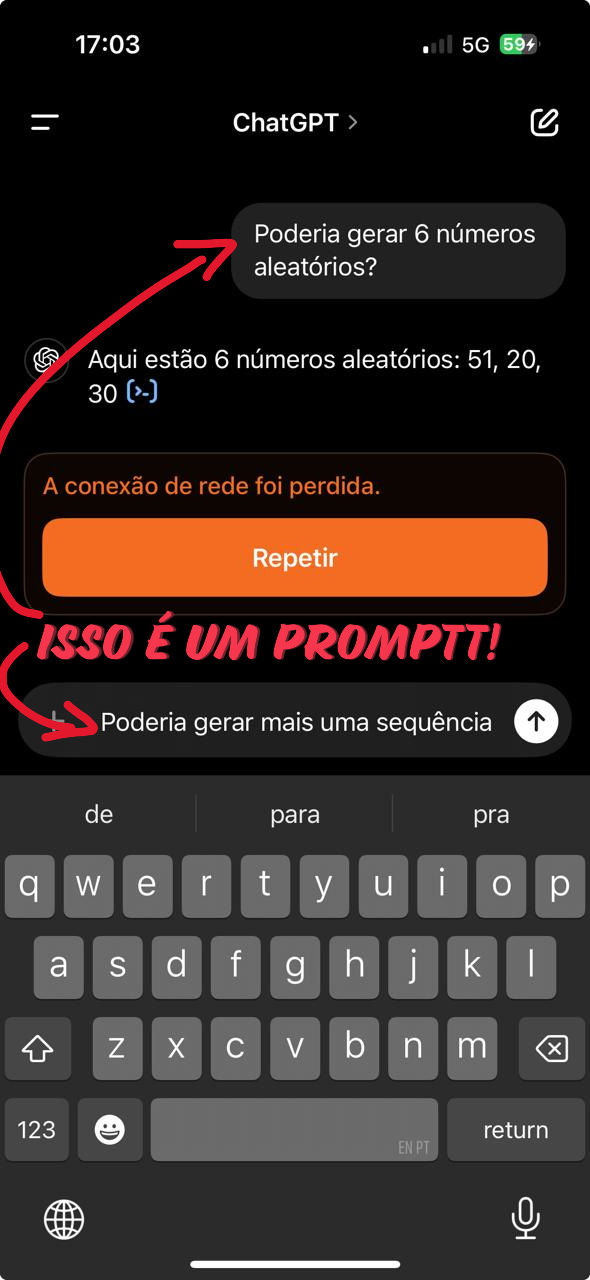
Um prompt é a entrada fornecida ao modelo de linguagem para que ele produza uma resposta. Ele orienta o modelo sobre o que se espera da saída. Por exemplo, se você pede a um modelo para “Gerar uma introdução para um artigo sobre IA,” esse é o prompt, que guia o modelo a criar um texto coerente e relevante para esse contexto.
O design de prompts, chamado de prompt engineering, é crucial para obter respostas precisas e úteis. Prompts bem construídos ajudam a maximizar a qualidade da resposta e a evitar ambiguidade, o que pode ser um diferencial entre uma saída útil e uma resposta genérica.
O Que São Tokens?
Tokens são as unidades básicas que um modelo de linguagem usa para processar texto. Em geral, um token representa uma palavra ou parte de uma palavra. Por exemplo, a frase “IA generativa é o futuro” pode ser dividida em cinco tokens: “IA”, “generativa”, “é”, “o”, “futuro.”

Para os LLMs, cada token representa um custo de processamento. Modelos mais avançados conseguem trabalhar com milhões de tokens, o que aumenta sua capacidade de contextualização, mas também torna o custo por token mais alto.
Como Funciona a Precificação dos Modelos?
A precificação dos LLMs é baseada em tokens. Em serviços como o OpenAI, você paga pelo número de tokens processados, tanto na entrada (prompt) quanto na saída (resposta). Essa estrutura permite um controle preciso dos custos, uma vez que você pode escolher o tamanho dos prompts e a complexidade das respostas desejadas.
Além disso, modelos mais avançados e potentes, como o GPT-4, têm uma tarifa mais elevada por token em comparação com modelos menores, como o GPT-3.5. Assim, há flexibilidade para usar o modelo mais apropriado para a tarefa em questão, ajustando o custo de acordo com a complexidade desejada.

O que ficar de olho?
Cada modelo tem um limite de entrada e saída. A escolha do modelo deve levar em consideração a quantidade de informação que você deseja trabalhar.
GPT-4 Turbo: 128K input / 4K output
Claude 3 Opus: 200K input / 4K output
Claude 3 Sonnet: 200K input / 4K output
Claude 3 Haiku: 200K input / 4K output
Gemini 1.5 Pro: 1M input / 8K outputExistem modelos que são melhores para tarefas específicas, avalie o problema que deseja resolver e escolha o modelo apropriado. Por exemplo, para língua portuguesa pode ser interessante o uso do maritaca (Maritaca AI | Modelos de linguagem) ao invés do GPT.
A Relação entre o Prompt e o Preço
A complexidade e o tamanho do prompt impactam diretamente o custo final de uso do modelo. Um prompt mais detalhado e específico tende a gerar respostas melhores, mas consome mais tokens, o que aumenta o custo. Da mesma forma, uma resposta longa e detalhada terá mais tokens e, portanto, será mais cara.
Ao considerar a precificação, uma boa prática é otimizar prompts para atingir um equilíbrio entre a quantidade de tokens usados e a qualidade da resposta. Ajustar a complexidade do prompt conforme o objetivo da tarefa pode ajudar a reduzir custos e ainda assim garantir respostas relevantes e de alta qualidade.
Dicas para construção de prompts
- Seja Claro e Específico: Quanto mais específico for o seu prompt, melhor será a resposta. Evite ser vago.
- Exemplo: Em vez de “Explique a teoria da relatividade”, tente “Explique a teoria da relatividade de Einstein em termos simples.”
- Contexto é Importante: Forneça contexto suficiente para que o modelo entenda o que você está pedindo.
- Exemplo: “Estou escrevendo um artigo sobre mudanças climáticas. Pode me dar uma visão geral das causas e efeitos?”
- Use Exemplos: Se possível, inclua exemplos no seu prompt para guiar o modelo.
- Exemplo: “Escreva uma introdução para um artigo sobre IA. Algo como: ‘A inteligência artificial está transformando o mundo de maneiras inesperadas.’”
- Perguntas Diretas: Faça perguntas diretas para obter respostas mais precisas.
- Exemplo: “Quais são os benefícios da energia solar?”
- Divida Tarefas Complexas: Se a tarefa for complexa, divida-a em partes menores.
- Exemplo: “Primeiro, explique o que é a energia solar. Depois, fale sobre seus benefícios.”
- Revise e Ajuste: Não hesite em ajustar seu prompt se a resposta não for o que você esperava. Pequenas mudanças podem fazer uma grande diferença.
- Use Formatos Diferentes: Experimente diferentes formatos, como listas, perguntas abertas, ou instruções passo a passo.
- Exemplo: “Liste cinco maneiras de reduzir o consumo de plástico.”
- Prompt negativo: Descreva explicitamente as coisas que você não quer que o modelo produza. Isso pode incluir não pedir informações sensíveis ou não gerar imagens de um estilo específico.
Conclusão
LLM como serviço oferece o uso de modelos de linguagem avançados de forma acessível. Entender o que são prompts e tokens, além da relação entre tamanho do prompt e precificação, é fundamental para usar esses modelos de forma eficiente. Ao utilizar LLMs, a habilidade em prompt engineering pode ajudar a controlar custos e obter respostas mais assertivas.