Clean Architecture e Java: atacando complexidade com complexidade
Neste artigo irei discutir um pouco sobre uma boa arquitetura para quando um software ficar complexo e conceitos como Clean Architecture e Domain Driven Design podem nos auxiliar nesses desafios.
Há um ponto importante que sempre discuto com quem quer que seja: complexidade desnecessária é desnecessária. A afirmação é extremamente redundante, mas a dificuldade de desenvolvedores que estão avançando em conceitos sobre Arquitetura, Orientação a Objetos, Padrões de Projeto etc, é definir qual a complexidade que aquele sistema necessita. Há quem diga que eu tenho pavor de classes, por exemplo. E é uma afirmação quase verdadeira, na verdade tenho pavor de criar classes de maneira desnecessária. Tenho pavor de criar heranças, composições, estruturas e o que mais for criado de maneira que adicione complexidade em algo que não há necessidade, já que há dois tipos principais de complexidade: complexidade de negócio — que é aquela que existe e o desenvolvedor tem de lidar com ela e transformar essa complexidade em um software que suporte a operação. E há a complexidade acidental — onde é a complexidade que nós, desenvolvedores, escolhemos seguir. Mas o contraponto principal é: problemas complexos exigem soluções complexas. E é a partir dessa afirmação que devemos seguir algumas considerações quando tratamos de arquitetura de software.
Arquitetura de Software
Um software tende a mudar. Qualquer desenvolvedor que já participou de algum projeto sabe que um software tende a mudar constantemente, seja com implementação de novas funcionalidades, melhorias das existentes ou com correções das mesmas (há quem diga que alguns deles simplesmente tendem a quebrar, mas isso já é outra história).
Quando temos isso em mente precisamos de uma estratégia para que esse crescimento não aconteça de maneira desenfreada e sem controle e a arquitetura de software vai nos ajudar a formatar esse software, auxiliando na criação de soluções realmente viáveis.
E como isso acontece? Arquitetura é sobre conseguir dividir claramente componentes, a comunicação entre eles e em como o planejamento estratégico pode se traduzir em código de maneira extensível. Esse é ponto principal de uma boa decisão arquitetural: deixar as coisas mais abertas a mudança, sem que essa mudança seja traumática para o software e/ou para a noite de sono dos desenvolvedores. No final do dia, arquitetura é sobre dar suporte ao ciclo de vida do sistema, garantindo que as decisões possam ser postergadas. Conseguindo essa proeza, facilita-se o processo de desenvolvimento, deploy, operação e manutenção desse sistema.
Clean Architecture e Domain Driven Design — Introdução
A Arquitetura Limpa foi criada por Robert C. Martin como uma filosofia de design de software e tenta nos guiar para um sistema independente. Ou seja: testável, independente de frameworks, independente de UI, independente de banco de dados e independente de qualquer agente externo.
![diagrama][https://miro.medium.com/v2/resize:fit:1400/format:webp/0*D433rkO2GP95y-Pp.jpg diagrama]
{kind=link}
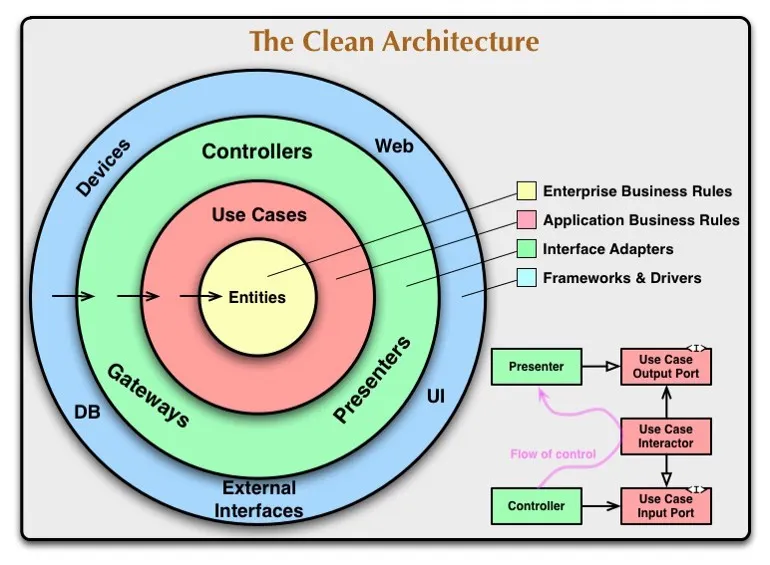
Como também disse no artigo anterior, este é o diagrama mais famoso sobre Arquitetura Limpa e é um belo retrato de como as coisas funcionam. Pense na seta como “depende”, portanto, a camada Framework & Drivers depende de Adaptadores de Interface, que por sua vez depende de Regras de Negócios da Aplicação que depende de Regras de Negócios da Empresa. Acompanhando? Mas lembre-se: O inverso nunca pode acontecer, em outras palavras: uma entidade nunca pode depender de um caso de uso, ou pior ainda — um framework.
O que isso tudo representa a nível prático? O real papel de um desenvolvedor de software. Há muita discussão a respeito da real necessidade futura de um desenvolvedor com tecnologias como ChatGPT surgindo e o fato dessa discussão ser real é o que realmente me assusta. O papel do desenvolvedor não deve nunca ser de escrever código — e essa afirmação pode parecer extremamente controversa para algumas pessoas, mas essa é a chave que vossa senhoria precisa virar. Um desenvolvedor de software resolve problemas, transforma regras de negócio em algo palpável e operacional a nível tecnológico. Na prática, isso faz muita diferença, tanto a nível de código em si quanto no valor entregado à empresa.
Imagine a seguinte situação: a empresa em que você está trabalhando chega com um novo projeto, um novo cliente e lhe apresenta o desafio: criar um sistema de monitoramento de gastos públicos das esferas Executivo, Federal e Estadual e emitir alertas públicos de gastos exorbitantes e aparentemente desnecessários. Há dois tipos de desenvolvedores e dois tipos de conversa que você pode ter com a gestão técnica que lhe apresenta esse projeto:
Qual linguagem nós usaremos para o back-end? Qual banco de dados? Qual framework front-end? Qual linguagem para scraping? Haverá sistema de fila? RabbitMQ? Kafka? Haverá Cloud centralizada? Peer to peer?
Qual a periodicidade de coleta das informações? O que será considerado um gasto exorbitante? Haverá cálculo de imposto em cima dos gastos? As empresas responsáveis pelo faturamento do gasto serão validadas? Alimentação terá teto de gasto?
Perceba que a primeira abordagem reflete detalhes. Esse é o maior vilão que quero que entenda nesse artigo. Se você puder aproveitar apenas um conhecimento que passarei aqui, que seja esse: decisões de detalhes devem ser a última coisa que o desenvolvedor deve se preocupar e não devem impactar nas nossas regras de negócio. E é exatamente isso que Eric Evans prega em seu livro — DDD — onde você deve atacar o coração do software, ou seja, Regra de Negócio. Caso detalhes de implementação estejam impactando na regra de negócio, é sinal de que não há uma delimitação eficiente da camada onde está atuando.
Bom, vamos continuar abordando os conceitos com um pouco de prática. Utilizaremos Java nesse artigo, mas tenha em mente que os conceitos aqui podem ser usados em qualquer linguagen — embora linguagens com suporte à orientação a objetos tenha conceitos que ajudam bastante a abstração da comunicação entre as camadas — que falaremos a seguir.
Sempre gosto de trazer o exemplo de um serviço de usuário para estudos que faço. Gosto desse exemplo porque é possível expandir o usuário para questões como autenticação, autorização, sistema de pontos, cashback, pagamento e outros vários casos. Agora não será diferente, vamos trabalhar com um microsserviço responsável por gerenciar os usuários de uma aplicação.
Casos de Uso
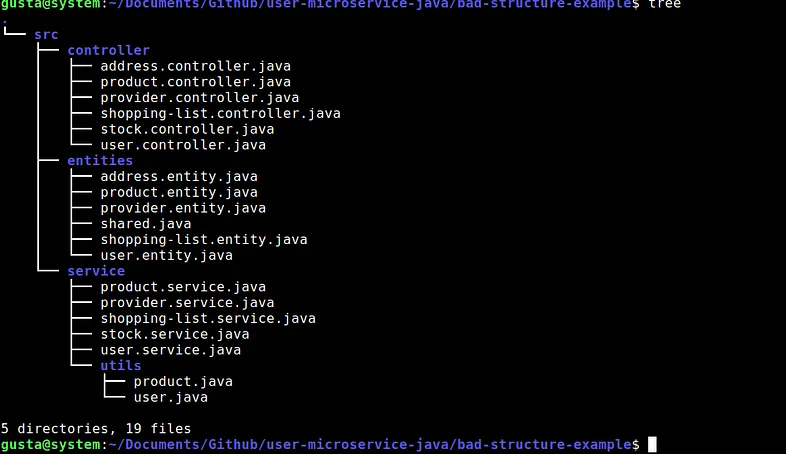
Quando falamos de Screaming Architecture estamos querendo que nossa arquitetura grite com expressividade o que o sistema realmente faz e o mais rápido possível, sem a necessidade de entrar em cada diretório, cada arquivo para realmente ter certeza do que aquilo faz — já dá pra ter claro que a partir daqui iremos tentar abolir qualquer existência de um Utils da vida, né? Vamos a um exemplo:
![badstructure][https://miro.medium.com/v2/resize:fit:786/format:webp/1*_VhUsjsZkVmCzPv1jCSxbw.png badstructure]
{kind=link}
Perceba que nesse exemplo de estrutura que não fazemos ideia do que esse sistema faz. Podemos ver que há uma lista de compra, um produto, usuário, mas o que ele REALMENTE faz? Ele cria um endereço? Ele consulta o endereço? O produto é criado e atualizado? Há exclusão de usuário? O que o utils faz? Um exercício que propuz uma vez é: exclua a importação de determinada função/classe. Agora chame uma pessoa que não sabe nada sobre como o sistema foi estruturado e peça a ele para apontar exatamente em qual arquivo essa função/classe se encontra.
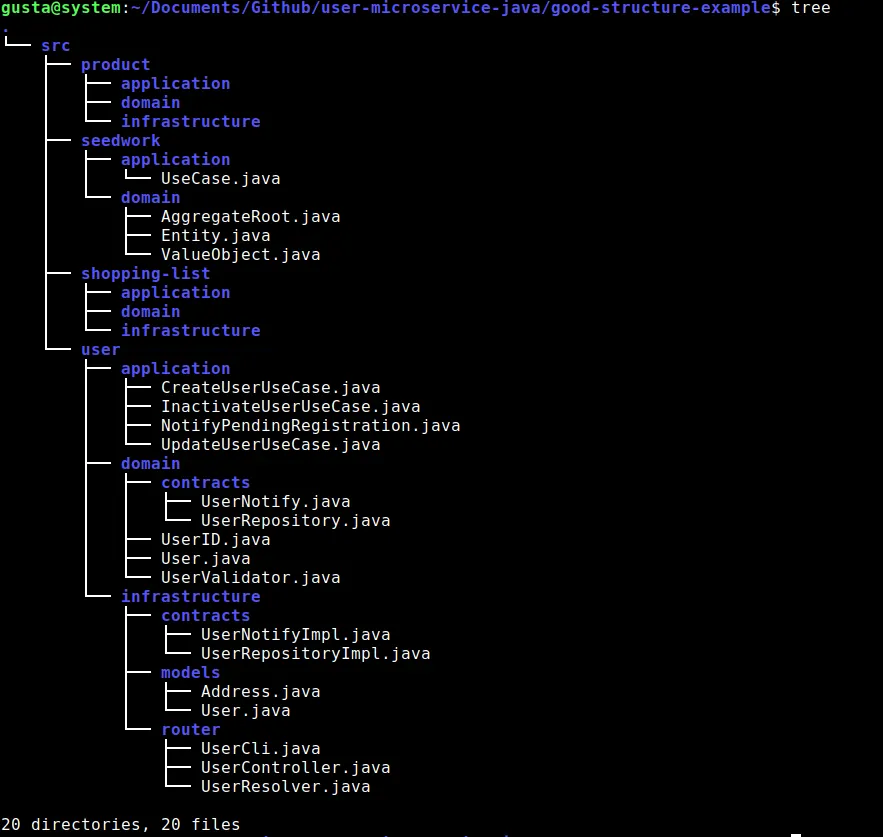
Óbvio, não é tão simplório quanto conseguir encontrar onde uma função está, mas você consegue ver que não há clareza a respeito do que o sistema faz e é aí que várias abordagens se tornam úteis, uma delas é orientar o seu sistema a casos de uso. Vamos dar uma olhada em como ficaria isso a nível organizacional:
![goodstructure][https://miro.medium.com/v2/resize:fit:1400/format:webp/1*Fw3sdeSLdyjwDX4rVaoi3g.png goodstructure]
{kind=link}
A árvore ficou um pouco maior, mas ficou extremamente mais claro o que o software realmente está fazendo. Óbvio, há várias coisas a melhorar, adicionar e talvez remover, mas a ideia é que quando tratamos de fluxos da aplicação, somos bem claros com o que queremos fazer. Não queremos um Serviço de Usuário, queremos Criar um Usuário e ter isso bem claro faz toda a diferença. Porém, embora seja mais claro do que está ocorrendo ali, precisamos sempre nos atentar: Clean Architecture não é sobre organização de pastas/diretórios, é sobre declarar sua inteção ao iniciar um fluxo no software, é sobre definir limites arquiteturais e não depender de detalhes na concepção e manutenção de uma funcionalidade.
Domain Driven Design — Modelagem Tática
Agora que já temos uma ideia de como iremos construir nosso software orientado a regras de negócio, temos que esclarecer que Uncle Bob deixa bem aberto em relação a como fazer isso a nível concreto. Uma ótima opção é utilizarmos padrões e modos de modelagem tática que Eric Evans nos contemplou em sua obra. Vamos dar uma olhada em alguns conceitos, primeiramente nas famigeradas Entidades:
public class User {
private Double id;
private String name;
private String email;
private boolean active;
private String password;
private LocalDate birthDate;
private Instant createdAt;
private Instant updatedAt;
private Instant deletedAt;
// construtor, getters e setters omitidos
}
Essa é a classe principal por representar o usuário da aplicação. Mas a questão é: essa classe representa uma entidade? Calma lá, precisamos definir três conceitos de Entidade que às vezes se confundem.
Entidade JPA: essa entidade representa a abstração da nossa tabela/collection do banco de dados. Não falaremos dela como Entidade daqui a diante. Para evitar confusões, costumo até chamar de Modelo de Banco de Dados, mesmo que a annotation que colocamos em cima da classe me desminta.
Entidade no Domain Driven Design: Aqui a entidade é tratada como identidade, algo que atribui valores e funciona através de mudança de estado, atribuída com um identificador único que pode fazer parte de um Agregado (falaremos adiante).
Entidade na Clean Architecture: Uncle Bob define a camada de entidade como toda a camada de regra de negócio.
A partir daí, podemos ver que a Clean Architecture não define muito bem como criar a camada de entidade, mas podemos utilizar os padrões táticos do DDD para nos auxiliar nessas tarefas, adicionando riqueza na nossa entidade e criando um objeto com verdadeiro motivo para existir, para ser alterado e gerar valor:
public class User {
private Double id;
private String name;
private String email;
private boolean active;
private String password;
private LocalDate birthDate;
private Instant createdAt;
private Instant updatedAt;
private Instant deletedAt;
public User inactivate() {
if (getDeletedAt() == null) {
this.deletedAt = Instant.now();
}
this.active = false;
this.updatedAt = Instant.now();
return this;
}
public boolean canBuyAlcohol() {
return Period.between(birthDate, LocalDate.now()).getYears() > 17;
}
}
Aqui temos o começo de uma representação real de uma entidade, de um local onde as regras de negócio do sistema estão encapsuladas e é aqui que a parte mais consistente e imutável do sistema deve estar. Repare também que evitamos criar getters e setters sem significado como setActive e passando como parâmetro um booleano. Ao invés disso, dizemos explicitamente o que queremos que o sistema faça, com um verbo claro da ação desejada.
Já temos nossa entidade criada? Bom, temos um começo, mas ainda temos um problema muito latente. Uma entidade deve estar sempre consistente, ou seja, deve estar sempre validada. Já vi lugares onde a criação da entidade era feita e a responsabilidade da validação da mesma era feita dentro do service ou caso de uso. De maneira prática: dá certo? Pode dar, mas o conceito por trás de uma entidade é que ela deve sempre se autovalidar, ou seja, nenhum objeto User deverá ser criado com algum tipo de inconsistência ou inválido.
public class User extends AggregateRoot<UserID> {
private User(
final Double id,
final String name,
final String email,
final String password,
final LocalDate birthDate,
final boolean active,
final Instant createdAt,
final Instant updatedAt,
final Instant deletedAt) {
this.id = id;
this.name = name;
this.email = email;
this.password = password;
this.birthDate = birthDate;
this.active = active;
this.createdAt = createdAt;
this.updatedAt = updatedAt;
this.deletedAt = deletedAt;
selfValidate();
}
public void selfValidate() {
final var notification = Notification.create();
validate(notification);
if (notification.hasError()) {
throw new NotificationException("Failed to create a user", notification);
}
}
public void validate(ValidationHandler handler) {
new UserValidator(this, handler).validate();
}
}
Há dois conceitos que não abordamos/abordaremos aqui — Notification Pattern e Validation Handler, mas fique tranquilo que o que nós precisamos entender por hora é que há uma camada que cuida das validações do usuário e uma outra que emite notificações de erro ao cliente do nosso sistema. Repare que o objeto User se auto valida em sua criação e deve fazer isso sempre que algum dado for alterado.
Outro ponto importante é a respeito do ID do usuário. Até o momento utilizamos um Double para representar um identificador único do usuário, mas vamos substituir essa abordagem por um UUID para que a ideia fique mais clara.
public class UserID extends Identifier {
private final String value;
private UserID(final String value) {
Objects.requireNonNull(value);
this.value = value;
}
public static UserID unique() {
return UserID.from(UUID.randomUUID());
}
public static UserID from(final String anId) {
return new UserID(anId);
}
public static UserID from(final UUID anId) {
return new UserID(anId.toString().toLowerCase());
}
@Override
public String getValue() {
return value;
}
}
Veja que agora nós não temos mais um simples Double representando o identificador único daquela entidade, temos um objeto completo que é criado e validado para que seja um valor único no sistema. Essa tática vale para outros campos também, como documento do usuário. Ao invés de criarmos um campo Documento do tipo String, podemos dar mais significado a esse campo, criando um Objeto de Valor que o representará. O objetivo é sempre dar mais semântica ao que está sendo representado no nosso sistema. Veja também que esses campos não devem seguir nenhum padrão ou igualdade com o nosso modelo de banco de dados, pois o documento pode continuar sendo uma simples String, um possível endereço pode ser uma String e na nossa entidade ser um objeto de valor que terá seu próprio objeto semântico.
E o que são esses Objetos de Valor? É um objeto básico que em sua essência não é único. Ou seja, se tivermos dois Objetos de Valor criados e eles tiverem os mesmos dados, eles podem ser considerados o mesmo. Isso já não ocorre para uma entidade.
Perceba também que agora o nosso User extende de um AggregateRoot. Primeiro vamos conceituar o que é o agregado em si.
Quando estamos iniciando um sistema, geralmente começamos a pensar no agregado e posteriormente em quais componentes há nele. Por exemplo, quando tratamos de um sistema de realização de pedidos de um restaurante, precisamos de um Usuário e esse usuário terá um Endereço. Essa relação entre o usuário e endereço é tão forte que nesse caso não faz sentido um endereço existir sem o usuário. A mesma coisa quando pensarmos em Pedido e os Itens do Pedido. Os itens do pedido não tem existência justificada se o pedido não estiver ali. Portanto, nesses casos teremos o agregado de Usuário e o agregado de Pedido. A partir daí ficou simples, né? O aggregate root é simplesmente o ponto central do agregado, no nosso caso, Usuário e Pedido, respectivamente.
Há muita teoria e muitos conceitos para assimilar, mas vamos nos concentrar em mais um: Repository. Esse é um padrão já bem conhecido e é basicamente uma camada onde há o armazenamento dos dados em que estamos trabalhando — lembre-se de que não é necessariamente uma abstração para o banco de dados.
Tratamos da teoria básica para construirmos nosso caso de uso a seguir:
public class DefaultCreateUserUseCase implements UseCase<CreateUserInput, CreateUserOutput> {
private final UserRepository userRepository;
public DefaultCreateUserUseCase(final UserRepository userRepository) {
this.userRepository = userRepository;
}
@Override
public CreateUserOutput execute(final CreateUserInput input) {
if (this.userRepository.findByEmail(input.email()).isPresent()) {
throw new UserAlreadyExistsException(input.email());
}
final User anUser = User.newUser(input.name(), input.email(), input.password(), input.birthDate(), true);
User createdUser = this.userRepository.create(anUser);
return CreateUserOutput.from(createdUser);
}
}
Esse é o fluxo da nossa intenção de criar um usuário. Todas as dependências que temos aqui são abstrações e construções que utilizamos para converter um dado a outro, sempre respeitando o contrato de que um caso de uso deve executar seu fluxo e ter uma entrada e uma saída definidos em si. A partir daí podemos verificar se há algum usuário cadastrado com o email passado, criar um usuário (totalmente validado e consistente) e salvar na nossa camada de persistência.
Essa é a ideia básica de trabalhar com Clean Architecture e utilizar algumas das táticas do Domain Driven Design. Há alguns outros padrões para abordarmos, como Domain Events, Domain Services, as Factories em si, Notification Pattern e outros, mas acredito que para demonstrar meu ponto isso já é suficiente no momento. Problemas complexos exigem soluções complexas, a partir do momento em que o seu sistema tende a escalar a nível de regra de negócio, de requisitos funcionais que o comportam e que há risco de haver atualização, melhoria e/ou modificação em sua regra, as coisas começam a ficar complexas. Qualquer pessoa que já trabalhou com aplicação de desconto e qualquer tipo de promoção sabe o quão simples algo pode nascer e quão complexo essa funcionalidade pode se tornar.
Novamente, eu abomino complexidade onde ela não se torna necessária. A partir do momento em que você opta por utilizar uma abordagem como Clean Architecture e DDD, você eleva o nível de qualificação necessária para o seu time de desenvolvimento ter um rendimento mínimo. É uma ótima forma de se trabalhar, mas você precisa ter consciência de que vai trazer um benefício real e financeiro para o projeto. Por fim, uma abordagem totalmente fidedigna se torna sem sentido em aplicações CRUD, onde não há uma regra de negócio forte para se tratar, mas com certeza os conceitos de separação de camadas pode facilitar um pouco as coisas, então não há necessidade de aplicar TUDO ou NADA dos conceitos abordados.
Tá, mas e o Spring? Quarkus? Qual banco de dados utilizaremos? Fila?
É aí que a mágica acontece. Não importa. Pelo menos não nesse momento. Não antes de toda a regra da aplicação estar bem definida e funcional. Há quem diga que pode haver uma equipe para cada camada (Domínio, Aplicação e Infraestrutura).
Se quiser saber mais sobre os conceitos que citei acima que não abordei nesse artigo ou saber como essas abstrações e regras funcionam de fato numa aplicação com um framework web plugado, é só me falar.
Não deixe de dar uma olhada no repositório do projeto e fique a vontade para contribuir de qualquer forma.