Algumas considerações sobre ASCII:
Se estiver trabalhando com ASCII, certamente o problema não irá ocorrer pois é uma tabela com apenas 256 códigos e cada código ocupa sempre um byte (0-255). A composição da tabela é a seguinte:
-
0-31 caracteres de controle.
-
32-127 caracteres imprimíveis (
+ - A a 9 /etc.). -
128-255 código estendidos.
Os códigos de 128-255 podem corresponder a símbolos diferentes dependendo da implementação. Mas continuam sendo um byte então, inverter uma string sempre vai funcionar. O problema aqui é que o À de uma tabela pode corresponder a um Ŕ da implementação em outra. Por exemplo:
ASCII Windows-1250 char(192) = Ŕ
ASCII ISO-8859-1 char(192) = À
Pessoalmente acho o Unicode muito bagunçado, no sentido de ter muita coisa inútil. Nem todas as fontes ttf possuem representação para todos os símbolos. Na realidade, algumas não possuem nem acentuação.
Acho os emoji legais para aquelas cartas enigmáticas que as crianças fazem. :D
O 🌞 + ⚄ foi 💤
Sobre o texto, me ocorre o que eu penso:
"O programador tem que escrever códigos legíveis e corretos mas ninguém ajuda o pobre coitado. Quem implementa os compiladores/interpretadores não pensa em facilitar a vida do programador que desenvolve sistemas para o mundo real.™. Este, por sua vez e com seu sangue de barata, acha que está tudo certo."
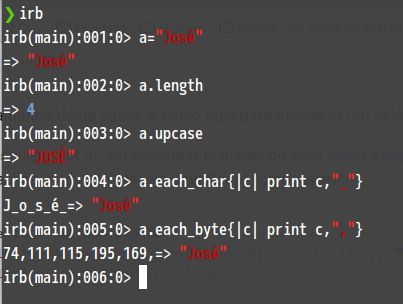
Eu penso que um caractere deixou de ser um byte há muito tempo. Uma string é uma sequência de caracteres e não de bytes. Vamos ignorar os emojis e se concentrar em um texto padrão. Supondo Josi e José.
-
Quem vem primeiro em ordem alfabética crescente?
José < Josi -
Como ficará a conversão para maiúsculas dos nomes?
José => JOSÉ -
Se procurar por
Joseo programa vai encontrar?José = Jose
Não uso Ruby, mas acho que isso deveria ser normal para qualquer linguagem que se preze (teria que ver se COBOL já não é assim). Caso contrário, eu considero beta, acadêmica ou prova de conceito (sim, eu uso linguagens que ainda são beta ;-) ).