Machine Learning sem código (parte 2)
Preparação dos dados
Agora que exploramos nossos dados e encontramos relações interessantes, podemos começar a testar alguns algoritmos de Machine Learning para completar a nossa tarefa de predizer quando o empréstimo deve ser concedido ou não. Mas para isso, precisamos preparar os dados.
Nessa etapa vamos tratar valores ausentes, criar variáveis dummy para dados categóricos e normalizar as variáveis numéricas.
Podemos fazer isso tudo de uma única vez criando um pipeline de pre-processamento dos dados. Basta usarmos o widget “Preprocessing”. Essa ferramenta nos permite selecionar as transformações que serão aplicadas nos dados e em qual ordem.
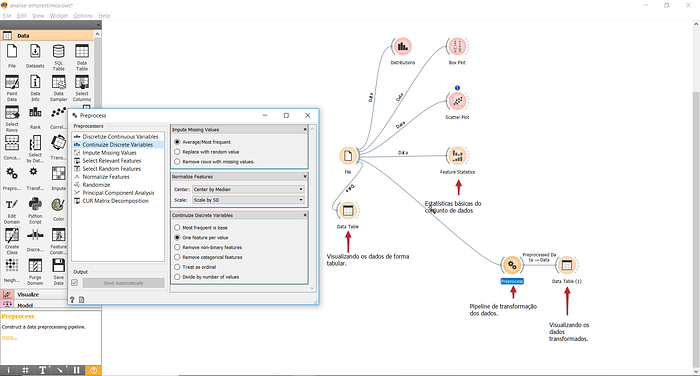
Criando um pipeline de transformação dos dados.
Para cada tratamento ou transformação, a ferramenta permite escolher entre várias abordagens. No nosso caso o nosso pipeline fará as seguintes modificações:
- Imputar os valores de dados ausentes usando a média para dados numéricos e a moda para variáveis categóricas;
- Normaliza os dados usando a mediana para centralizá-los. Como vimos, o conjunto de dados possui alguns outliers e por isso, escolhemos centralizar os dados com base na mediana, que não é afetada por valores extremos.
- Por fim, transformamos as variáveis categóricas em variáveis dummies. Ou seja, variáveis binárias. Para cada valor de cada uma das variáveis categóricas, uma coluna é criada contendo valores apenas de 0 e 1. Um indica que a observação em questão possui o valor da variável. Olhando o conjunto de dados fica mais claro:
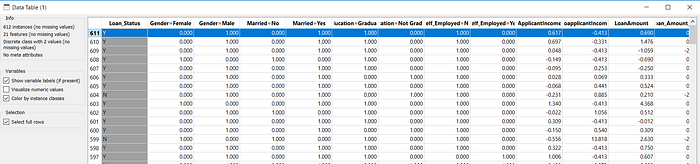
Dados transformados.
A linha em destaque indica que o cliente é do sexo masculino (coluna Gender=Male com valor 1). Para ficar mais claro, pense nisso como uma pergunta: O cliente do pedido 611 é do sexo masculino ? SIM(True, ou 1).
Parece que temos o conjunto de dados pronto para alimentar um algoritmo, mas ainda não. No exemplo acima, vimos que temos uma coluna para indicar se o cliente é do sexo masculino e outra para indicar se o cliente é do sexo feminino. Na verdade, só precisamos saber se o cliente é de um dos dois sexos, pois obviamente não será do outro. Portanto, podemos excluir uma das duas colunas(Gender=Male ou Gender=Female). O mesmo acontece para as variáveis Married, Credit_History, Education e Self_employed.
Vamos fazer isso usando o widget “Select Columns”:
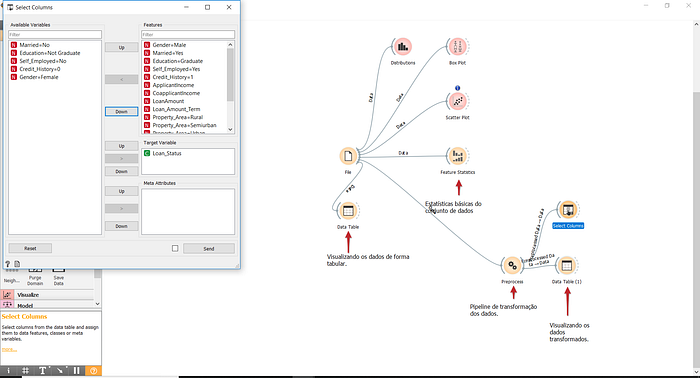
A esquerda as variáveis que removemos do conjunto de dados e a direita, as que serão mantidas.
Agora sim nossos dados estão prontos para um algoritmo de ML. Então vamos para a etapa de modelagem.
Testando e avaliando alguns modelos
Para começar escolheremos um algoritmo amplamente utilizado em mineração de dados: a Árvore de Decisão. A lógica por trás desse algoritmo é extremamente simples o que de maneira alguma torna o algoritmo menos poderoso.
A ideia central é encontrar características no conjunto de dados que sejam discriminantes em relação a variável alvo. O modelo está sempre buscando grupos de dados agrupados com base em características que garantam o maior ganho de informação e pureza nos dados. Quando falamos em ganho de informação, isso significa literalmente encontrar características que nos deem informações para determinar se o empréstimo foi concedido.
Por exemplo, já percebemos que a variável Credit_History é informativa sobre a concessão do empréstimo ou não, pois a maioria dos empréstimos é concedido para quem tem histórico de crédito com o banco. Logo, essa característica nos dá uma informação importante sobre a concessão de empréstimos.
Para aplicar um algoritmo só precisamos escolher um deles na aba “Model” e conectar aos dados preparados:
Aplicando o algoritmo no conjunto de dados
Após aplicar o algoritmo, podemos ver a árvore de decisões que foi criada usando o widget “Tree Viewer”:

E aí está a nossa árvore de decisão, entendê-la também é muito simples. A árvore começa com a feature Credit_History, apenas confirmando nossa análise de que essa informação é muito importante para a concessão do crédito.
Seguindo as ramificações para a direita, vemos que ter uma propriedade semi-urbana também tem um alto impacto na variável alvo, em seguida percebemos que ter um Coapplicant com renda maior que 150 e um valor de empréstimo inferior a 7101 aumenta as chances de concessão do crédito.
Portanto, a lógica para concessão do empréstimo ficaria mais ou menos assim:
Cliente com histórico de crédito no banco → propriedade semi-urbana → coapplicant (co-solicitante) com renda superior a 150 → valor de empréstimo inferior a 7100 → Conceder empréstimo.
Para quantificar o quão bom é o nosso modelo podemos utilizar algumas métricas de avaliação, vamos começar com Acurácia. A acurácia é uma das métricas mais utilizadas para avaliação do desempenho de modelos de classificação, embora nem sempre seja a métrica mais recomendada.
Vamos ver o desempenho do nosso modelo usando o widget “Test & Score”. Esse widget, recebe como entrada os dados pre-processados e o modelo treinado. Então é aplicada a técnica de validação cruzada para avaliar o desempenho do modelo em vários conjuntos de dados diferentes.
Isso é feito dividindo o conjunto de testes em N grupos distintos, no nosso caso 5. Então o modelo é treinado em quatro grupos e é validade no quinto. Esse processo é repetido até que o modelo tenha sido validado em cada um dos agrupamentos.
Então, calcula-se a média de cada uma das métricas de avaliação com base no desempenho de cada validação.

Avaliando o modelo usando validação cruzada.
Acurácia média do modelo(CA) foi de 78%. Isso quer dizer que, de 10 previsões, o modelo acerta praticamente 8. Nada mal para começar !
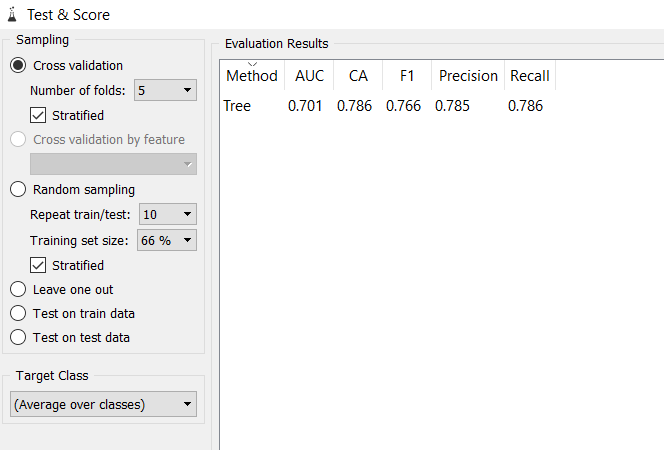
Desempenho do modelo de árvore de decisão
Uma outra maneira de avaliar o desempenho do nosso classificador é observar a matriz de confusão. O nome pode assustar um pouco, mas na prática é bem intuitivo. A matriz de confusão pode ser criada com o widget “Confusion Matrix”:
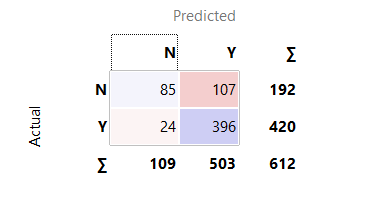
Matriz de confusão
Vamos entender:
As linhas indicam os valores reais da nossa variável alvo, e as colunas indicam as previsões do nosso modelo. Se olharmos a primeira coluna vamos perceber que quando o modelo previu que o empréstimo não seria concedido acertou 85 vezes e errou 24 , totalizando 109 previsões negativas.
Já na segunda coluna vemos que o modelo previu que o empréstimo seria concedido 503 vezes e desse total, ele previu corretamente em 396 dos casos. Essa análise nos ajuda a entender onde o modelo está errando e nos dá insights sobre como ajustar nosso classificador.
O Orange ainda nos permite ainda comparar o desempenho de vários modelos diferentes.
Comparando modelos
Vamos usar um algoritmo mais poderoso: Floresta Aleatória.
Esse algoritmo se enquadra na categoria de classificadores que utilizam métodos de ensemble learning. De forma simples: algoritmos que empregam este método se baseiam nas previsões de vários outros classificadores para gerar uma classificação mais precisa.
Cada modelo vota em uma classe e a classe com mais votos é utilizada na previsão.
Como sempre, ver sempre facilita as coisas:

Método ensemble fonte: Hands-on Machine Learning with Scikt Learn and Tensor Flow
No caso da Floresta Aleatória, são criados vários modelos de Árvores de Decisão, daí o nome do algoritmo.
Vamos aplicar este modelo aos nossos dados e comparar com os resultados da árvore de decisão. O procedimento é exatamente igual à aplicação da árvore de decisão.

Resultados árvore de decisão Vs floresta aleatória
Realmente a Floresta Aleatória tem um desempenho muito superior. A acurácia saltou de 78 para 80%.
Para ficar mais claro, podemos ainda visualizar as previsões de cada um dos modelos para cada uma das instâncias(linhas) do nosso conjunto de dados. Como de costume, é só clicar, conectar e clicar duas vezes. O widget da vez é o “Predictions”.
Aqui, usamos os dados e cada um dos modelos como entrada:
Conhecendo as previsões de cada um dos modelos
Agora clicando duas vezes no ícone “Predictions”, temos a seguinte tabela:
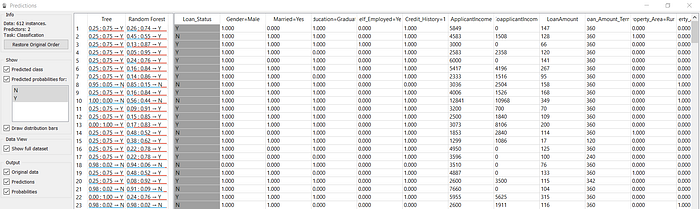
As previsões de cada um dos modelos
Além de nos mostrar a previsão de cada um dos modelos, esse widget também nos mostra a probabilidade atribuída a cada uma das classes.
Por exemplo, na linha número 12, ambos classificadores previram que o empréstimo seria concedido e ambos acertaram. Repare que a Floresta Aleatória tinha uma confiança muito maior em sua previsão (85% de probabilidade de conceder o empréstimo, contra 75% da árvore de decisão).
Também podemos ver onde os classificadores erraram, na imagem acima, a linha 19.
Conclusão e informações adicionais
Neste artigo nós passamos por praticamente todo o fluxo de trabalho de um projeto de mineração de dados. Lembrando:
- Carregamos e visualizamos nosso dados em formato tabular;
- Exploramos os dados visualmente usando box-plots, gráficos de frequência e dispersão;
- Criamos um pipeline para limpar e transformar os dados para que ficassem prontos para o algoritmo ;
- Treinamos não apenas um, mas dois algoritmos de aprendizado de máquina supervisionado em nosso conjunto de dados;
- Avaliamos e comparamos o desempenho de cada um dos modelos;
- Visualizamos as previsões de algumas instâncias específicas bem como a probabilidade atribuída para cada classe.
Tudo isso foi feito de maneira simples e intuitiva utilizando o Orange uma ferramenta que facilita muito o processo de trabalho de mineração de dados. Vale ressaltar que a ideia aqui não é convencer ninguém a abandonar as linguagens de programação, mas sim apresentar mais uma opção para ter no seu arsenal de cientista de dados, o Orange pode ser utilizado para a extração de insights rápidos de forma prática, para testar novos métodos ou até mesmo como uma porta de entrada para o fascinante mundo do aprendizado de máquina.
Espero que tenha conseguido demonstrar pelo menos um pouco das técnicas de análises avançadas de dados que o Orange oferece e que a partir daqui você seja capaz de desbravar todas elas por si só e aprender cada vez mais sobre essa maravilhosa ferramenta.
Aqui vão alguns links para você continuar explorando seus dados usando Orange:
Para os leitores que querem entender mais a fundo alguns termos e técnicas abordadas, seguem alguns links interessantes:
- Ensemble Learning: https://en.wikipedia.org/wiki/Ensemble_learning
- Floresta Aleatória: Neste artigo Will Koehrsen mostra em detalhes a implementação de um modelo de Random Forest. Esse cara é fera, vale muito a pena acompanhar suas publicações !
- Árvores de Decisão: Neste artigo, o autor explica de maneira muito clara como funcionam as árvores de decisão. Vale a pena conferir.
- Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems: Esse livro é excelente para quem quer entender como funcionam as métricas de avaliação de classificadores e por que a acurácia em muitos casos não é a melhor métrica de avaliação para um classificador.
- Os dados utilizados podem ser baixados neste link. Para ter acesso, você deve criar uma conta no site Analytics Vidhya e se inscrever na competição Loan Prediction Practice Problem (Using Python), é totalmente free e uma excelente oportunidade para entender o básico de problemas de classificação.
Bom acho que é isso, espero que tenham gostado e qualquer dúvida comentário ou observação é mais do que bem vinda ! Não deixe de se manifestar, vamos aprender juntos !
Muito obrigado a todos e #keeplearning !