Machine Learning sem código (parte 1)
Usando Orange Data Mining para criar um modelo preditivo sem usar uma linha de código!

O Orange, os dados e seus amiguinhos(widgets)!
Orange Data Mining é uma ferramenta open source que permite criar todo fluxo de trabalho de um projeto de data mining, sem necessidade de código. Ideal para quem quer praticar machine learning mas não pretende aprender a codificar ou para iniciantes que pretendem aplicar alguns conceitos, bem como para experts no assunto.
O Orange Data Mining possui uma interface drag and drop. Similar a algumas ferramentas como SPSS Modeler e Azure ML da IBM e Microsoft, respectivamente. Particularmente me parece que os tutoriais sobre o Orange são muito mais escassos e essa ferramenta embora muito boa, ainda é pouco conhecida. Em geral, não vemos muitos tutoriais de ferramentas mais acessíveis para praticar machine learning e com a popularização da mineração de dados tudo indica que a demanda por esse tipo de ferramenta tende a crescer mais e mais.
Não tenho a intenção de dizer que R e Python não são bons para o uso em mineração de dados. Na verdade ao meu ver são as ferramentas ideais para essa finalidade, por darem grande poder de processamento e customização para o usuário, mas como é de se esperar exige muito mais dedicação. Inclusive é possível usar scripts Python no próprio Orange.
A ideia desse artigo, é mostrar que ML não é um bicho de sete cabeças e muito menos é necessário ser um gênio da informática ou da matemática para aplicar essas técnicas.
Na verdade, com algum conhecimento das principais técnicas e conceitos e um pouco de curiosidade, arrisco dizer que qualquer pessoa pode realizar uma análise realmente poderosa usando machine learning.
Vamos em frente e conhecer um pouco mais dessa grande ferramenta que pode ser útil até para aqueles que preferem usar código para suas análises(como é o meu caso..rsrs).
Conhecendo o Orange

Interface do Orange
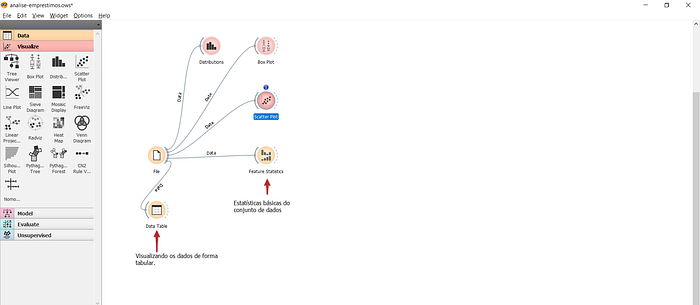
Essa é a interface do Orange. A esquerda temos 5 abas e cada uma agrupa uma gama de funcionalidades e técnicas de mineração de dados. Vamos dar uma rápida olhada:
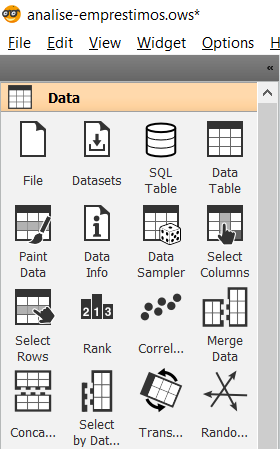
- Data: Cada ícone(ou widget) representa uma ferramenta ou técnica para ser utilizado no processo de carga e preparo dos dados. É possível desde incluir dados ausentes, criar features, discretizar variáveis contínuas entre tantas outras técnicas comumente aplicadas;
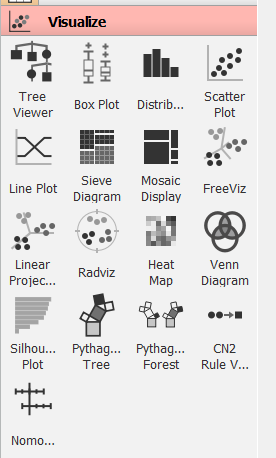
- Visualize: Como o nome sugere, trata-se do grupo de ferramentas para visualização de dados. É possível fazer gráficos de dispersão, box-plots, gráficos de linha e etc.
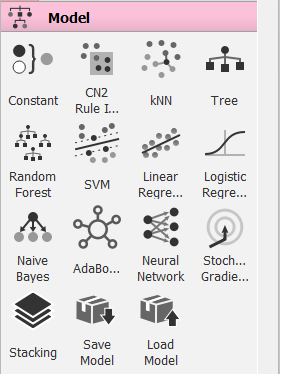
- Model: Essa aba contém os principais modelos que podemos utilizar em data mining. Todos eles são modelos supervisionados. Temos desde os modelos mais simples, como a Regressão Linear, até modelos mais complexos, como Redes Neurais;
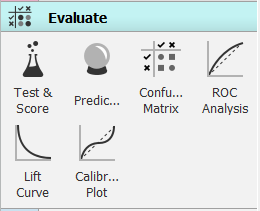
- Evaluate: Aqui podemos contar com as técnicas para avaliar o desempenho dos modelos criados. Matriz de confusão, análise AUC e validação cruzada estão disponíveis aqui;

- Unsupervised: Por fim, temos os modelos de aprendizado não supervisionado como K-means e alguns algoritmos comumente utilizados para transformação dos dados, como por exemplo a PCA.
Conhecendo o projeto
Agora que temos uma visão geral das ferramentas disponíveis dentro do Orange, podemos começar o nosso projeto.
O conjunto de dados que será utilizado, simula as características de clientes que pediram empréstimo para um banco e tiveram ou não a solicitação aprovada. Nossa missão é criar um modelo preditivo que determine quando um empréstimo deve ser concedido ou não.
De acordo com o site essa é a descrição das variáveis que compõem o conjunto de dados:
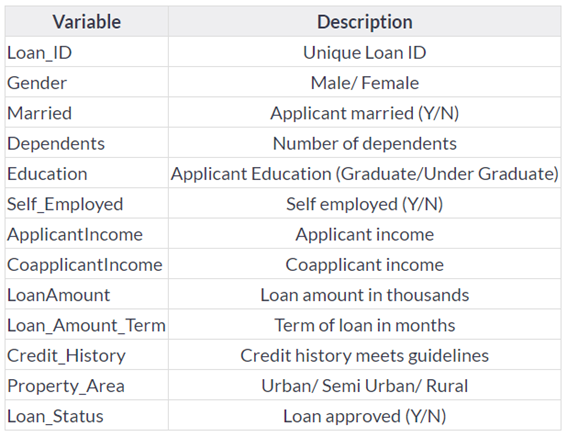
Variáveis do conjunto de dados
Como temos a variável resposta(empréstimo concedido: S ou N), estamos lidando com um problema de classificação binária, logo, teremos que usar os algoritmos que se enquadram na categoria de aprendizado supervisionado.
A seguir, vamos passar pelas principais etapas de um projeto de mineração de dados e ver como o Orange pode nos ajudar em cada uma delas.
Carregando os dados
Para carregar um conjunto de dados no Orange é muito simples. Basta clicar no widget “File” e selecionar o conjunto de dados na pasta onde ele está salvo. Simples como abrir um arquivo no Excel.
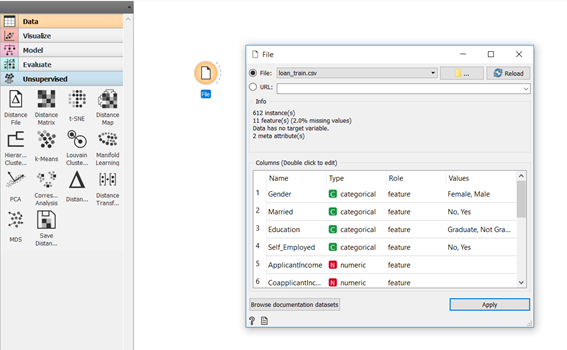
Além disso, como de praxe em ferramentas como Power Bi e Tableau, já temos uma visão geral dos dados e os tipos de features do dataset. Temos 612 linhas, 11 features(colunas) e cerca de 2% de dados ausentes.
Aqui é possível classificar cada uma das variáveis do conjunto de dados como numérica ou categórica, bem como determinar qual é a nossa variável alvo. Também podemos selecionar quais colunas queremos importar, no caso, não queremos usar a coluna Loan_Id e a nossa variável alvo é Loan_Status.
Após importar os dados, podemos visualizá-los de forma tabular. Isso também é muito simples. Basta clicar no ícone “Data Table”, e em seguida conectá-lo com “File”, então, clicamos duas vezes em “Data Table” e pronto:
Ao clicar em qualquer um dos widgets nas abas da esquerda, uma cópia surge no work space
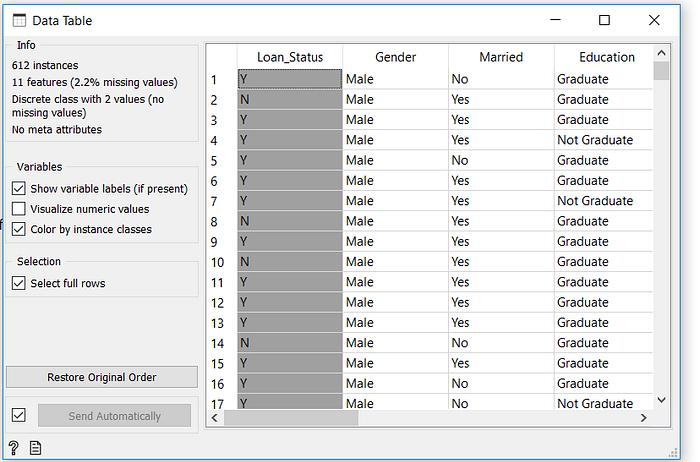
Nosso conjunto de dados
Análise Exploratória
Dados carregados, agora podemos conhecê-los um pouco melhor. Um ótimo começo é avaliar algumas estatísticas básicas das colunas do conjunto de dados. Podemos fazer isso usando “Feature Statistics”:
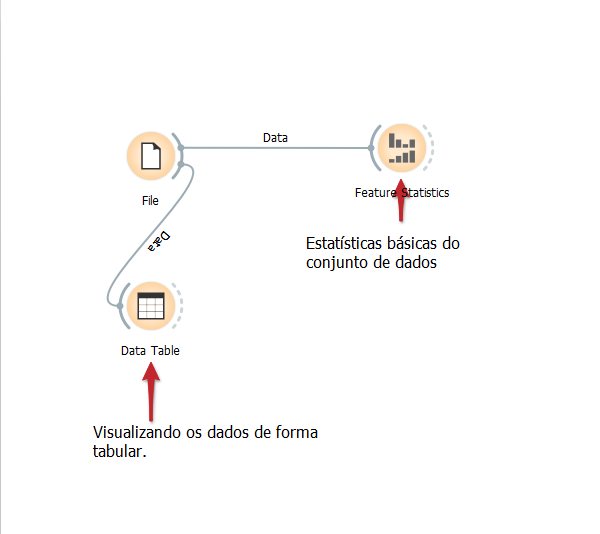
Clicando duas vezes no ícone temos:

Similar a função describe() do Pandas.
Podemos ver a média, valor máximo e mínimo de cada variável numérica, além da moda das variáveis categóricas. Também podemos ver o percentual de valores nulos em cada variável.
Outra ótima opção disponível nessa ferramenta, é que podemos visualizar a distribuição dos dados agrupada pela variável alvo(ou por qualquer outra que você prefira). Com isso, conseguimos descobrir que pessoas com histórico de crédito tem uma chance muito maior de ter o empréstimo aprovado do que pessoas sem histórico. Vejam:
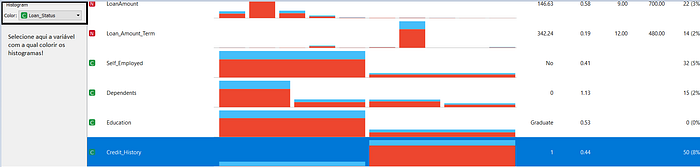
Azul: empréstimo negado / vermelho: empréstimo concedido
Também descobrimos que o valor médio do empréstimo é de 146 mil e o valor médio de renda dos solicitantes é de 5412. A maior parte dos solicitantes são casados, não tem dependentes e possuem graduação.
Visualizando os dados
Tá legal, eu admito. Os gráficos acima não estão tão convidativos. Sabemos que usar gráficos durante no processo de exploração dos dados é uma poderosa técnica que permite encontrar padrões importantes e entender melhor as relações nos dados. O ideal é que essas visualizações sejam claras e informativas.
Mais uma vez, só precisamos selecionar o ícone do gráfico desejado na aba “Visualize”, conectar aos nossos dados e clicar duas vezes no ícone.
Vamos começar usando um box-plot para ver a distribuição da variável ApplicantIncome.
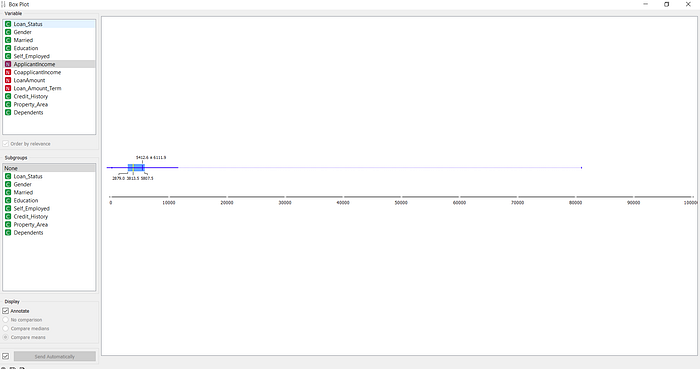
Box-plot da renda do solicitante do empréstimo.
Agora podemos ver com clareza as principais medidas de distribuição dos dados. A renda média é de 5412** enquanto que a **mediana é de 3813, indicando que essa variável tem uma distribuição com uma longa calda para a direita.
A média possivelmente está sendo distorcida pela presença de outliers, no caso, temos um solicitante com renda de mais de $80 mil.
Também podemos plotar gráficos agrupados por variáveis categóricas. Por exemplo, podemos ver a distribuição do valor do empréstimo entre homens e mulheres:
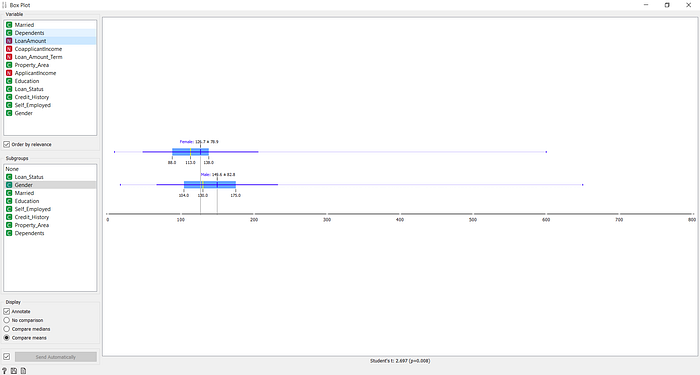
Distribuição do valor do empréstimo entre homens e mulheres.
Com base neste gráfico, podemos ver que homens geralmente pedem empréstimos com valores mais altos. O valor mediano do empréstimo para os homens é de 130 mil, enquanto que para as mulheres é de $113mil.
A seguir vamos explorar as distribuições dos dados numéricos usando o widget “Distribuitions”:
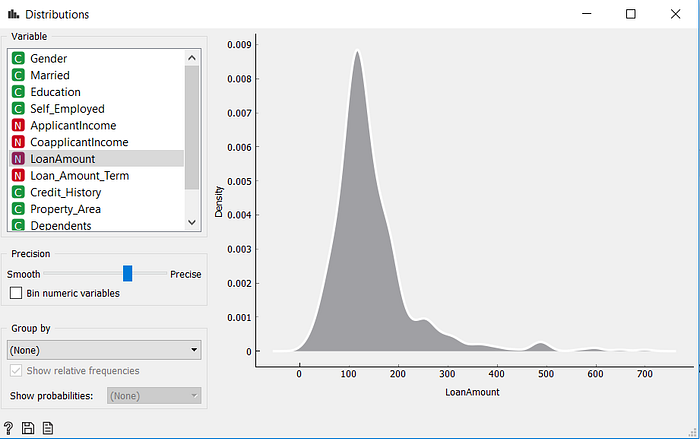
Gráfico de densidade do valor de empréstimo solicitado.
Mais uma vez, podemos fazer agrupamentos pelas variáveis categóricas. E conforme vemos abaixo, parece que a variável Property_Area influencia na decisão da concessão do empréstimo. De todos empréstimos concedidos, 42% são de clientes cujo valor de Property_Area era Semiurban. Já dos que não conseguiram, 70% eram das áreas Rural ou Urban.
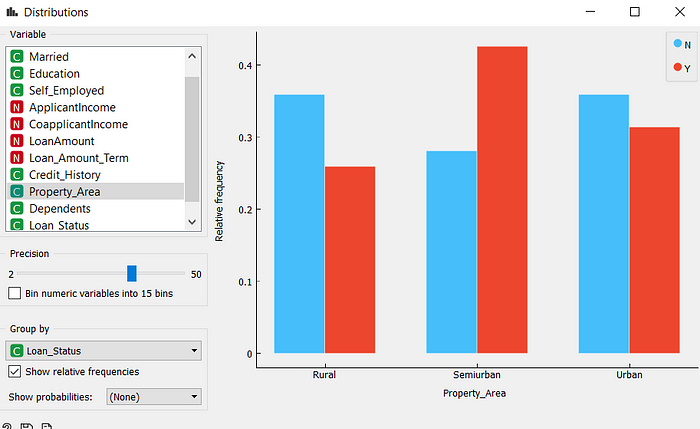
Frequência relativa do status de empréstimos de acordo com a área da propriedade
Outra maneira de explorar os dados visualmente é usando gráficos de dispersão. Esses gráficos nos permitem entender relações entre variáveis numéricas contínuas. No gráfico abaixo, vemos que há uma correlação positiva entre o valor da renda do solicitante do empréstimo e o valor solicitado. Sugerindo que pessoas com maior valor de renda, pedem empréstimos maiores.
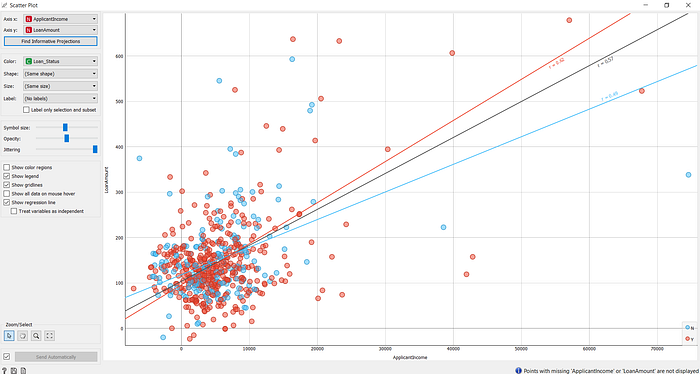
Relação entre renda e valor do empréstimo.