[My notes] Compiladores - Parsing
Aviso!
Este post é uma parte das minhas anotações pessoais sobre compiladores, ou seja ainda não cobre todos os fundamentos, creio que farei outros posts com outras anotações sobre as outras etapas de compilação.
Bom, está area é gigantesca e seria impossível aprender tudo de uma vez, mais creio que consiga aprender os fundamentos pelo menos :D.
Introdução
Compiladores são sofwares cujo o único objeto é transformar uma estrutura gramatical(ou linguagem) em outra linguagem. Muito além disto podemos observar que eles são transformadores e otimizadores, eles corrigem muita coisa errada que fazemos.
Partes
Bom, compiladores são divíduos em algumas partes, sendo elas:
- Parsing
- Transformation
- Code generation
Parsing
Está fase da compilação é responsável em pegar nosso código de entrada, e transforma-lo em uma estrutura organizada, conhecida como AST(Abstract Syntax Tree), resumidamente pelo que entendi seria uma visão simplificada do que foi escrito em formato de arvore.
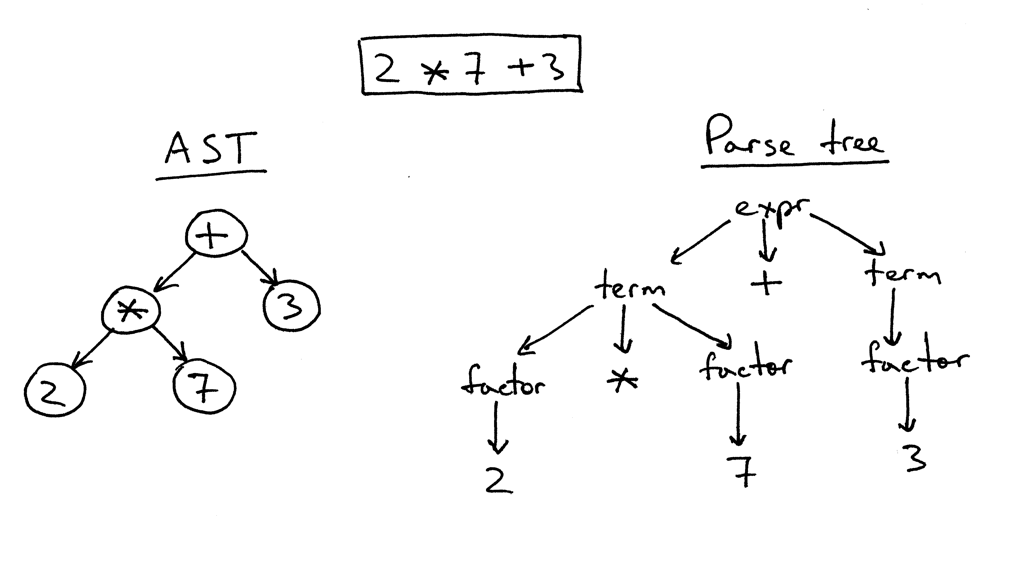
O parsing tem 2 fases, sendo elas:
- Analise léxica
- Analise sintática
Analise léxica
Bom a analise léxica separa o código "puro" em partes, e estas partes serão chamadas comumente de tokens que podem ser classificados como pontuações, números, operadores e etc. essa separação geralmente é feita por algo que pode ser chamado de tokenizer, chamaria ele de classificador por ele classificar textos sem significado, contudo por convenção é utilizado tokenizer.
Exemplo de tokenizer: https://github.com/lydell/js-tokens
Analise sintática
Feita a analise léxica a analise sintática traz mais significados a esses tokens perdidos estabelecendo relações entre eles.
Exemplo
Para uma sintaxe como está:
print('Hello World')
imagino que teríamos tokens parecidos com isto:
[
{ type: 'name', value: 'print' },
{ type: 'paren': value: '(' },
{ type: 'text', value: 'Hello World' }
{ type: 'paren': value: ')' },
]
obs: Penso eu que de para separar melhor, contudo não consegui pensar em nada no momento :P.
Imaginei uma AST para estes tokens e pensei nisto:
{
body: [
{
type: 'CallFunction',
name: 'print',
params: [
{
type: 'String',
value: 'Hello World'
}
]
}
]
}
obs: este daqui está extremamente simplificado poderíamos discutir muito de como a essa string poderia ser representada, mais por agora creio que esteja ótimo, porém caso queira o python tem uma biblioteca chamada ast, que como o proprio nome diz consegue fazer ASTS utilizando a gramatica da linguagem
Bom, após estes estudos tentei aplicar os conceitos apreendidos(principalmente a tokenização) em um projeto de uma biblioteca que transforma rotas em texto em regex, segue o código: https://gitlab.com/diegogitlab03/path-to-regexp