Desbravando work_mem: Otimização de queries no PostgreSQL
Briefing
Anos atrás, recebi a missão de investigar e resolver a lentidão em um sistema crítico da firma. Foram noites mal dormidas e alguns fios a menos de cabelo. O backend utilizava PostgreSQL e, depois de muito suor e investigação, a solução veio em literalmente uma linha:
ALTER USER foo SET work_mem='32MB';
Sendo sincero, este conteúdo pode ou não resolver seu problema de maneira imediata, vai depender muito do padrão das queries do seu sistema. Mas, se você trabalha com backend, espero que este post traga mais uma opção no seu arsenal para resolver problemas de performance, especialmente envolvendo PostgreSQL 😄.
Ao longo do post, vamos montar um cenário que facilita a degradação de performance e explorar algumas ferramentas pra investigar o problema a fundo, como o EXPLAIN, o k6 pra testes de carga, além de arriscar uma olhada no código-fonte do PostgreSQL. Também vou compartilhar alguns artigos que podem dar uma direção pra resolver problemas parecidos.
Cenário
Vamos criar um sistema simples para analisar o desempenho de jogadores de futebol, por enquanto, a única necessidade de neǵocio é responder a seguinte pergunta:
- Qual o top N dos jogadores que mais tiveram participações em gols?
Para responder a essa pergunta, vamos modelar nosso banco de dados com três tabelas. O SQL a seguir cria e popula essas tabelas:
CREATE TABLE players (
player_id SERIAL PRIMARY KEY,
nationality TEXT,
age INT,
position TEXT
);
CREATE TABLE matches (
match_id SERIAL PRIMARY KEY,
match_date DATE,
home_team TEXT,
away_team TEXT
);
CREATE TABLE player_stats (
player_stat_id SERIAL PRIMARY KEY,
player_id INT REFERENCES players(player_id),
match_id INT REFERENCES matches(match_id),
goals INT,
assists INT,
minutes_played INT
);
-- Populate players with a range of nationalities, ages, and positions
INSERT INTO players (nationality, age, position)
SELECT
('Country' || (1 + random()*100)::int), -- 100 different nationalities
(18 + random()*20)::int, -- Ages between 18 and 38
(ARRAY['Forward', 'Midfielder', 'Defender', 'Goalkeeper'])[ceil(random()*4)::int]
FROM generate_series(1, 10000);
O script para inicializar e popular o banco de dados está no repositório do GitHub.
E sim, poderíamos modelar os dados de forma que as queries fossem mais performáticas, mas o objetivo aqui é justamente explorar cenários não otimizados. Acredite, você provavelmente vai encontrar sistemas onde é preciso "tirar leite de pedra" para conseguir performance, seja por erros de modelagem ou crescimento inesperado.
Debugando o Problema
Para simular o problema envolvendo o valor do work_mem, vamos formular a query para responder: Qual o top 2000 dos jogadores que mais contribuíram com gols? Ou seja, o somatório de assistências e gols por player_id, ordenado de forma decrescente:
SELECT p.player_id, SUM(ps.goals + ps.assists) AS total_score
FROM player_stats ps
JOIN players p ON ps.player_id = p.player_id
GROUP BY p.player_id
ORDER BY total_score DESC
LIMIT 2000;
Tá, mas como identifico possíveis gargalos nessa query? Não só o PostgreSQL mas como outros DBMS do mercado suportam o comando EXPLAIN que detalha a sequência de passos, ou o plano de execução otimizado (ou não), que precisará ser percorrido e executado dado a query em questão.
Podemos ver informações como:
- Qual o tipo da busca? Index scan, Index Only scan, Seq Scan, etc.
- Qual índice foi utilizado? E por qual condição?
- Se houver Sort, qual foi o algoritmo utilizado? Utilizou memória ou disco?
- Uso de shared buffers.
- Estimativas de tempo de execução.
Você pode encontrar mais sobre o planner/optimizer em:
- documentação oficial
- pganalyze - basics of postgres query planning
- cybertec - how to interpret postgresql explain
Talk is cheap
Falar é fácil, então vamos análisar um exemplo prático. Primeiro vamos diminuir o work_mem para o menor valor possível, que é 64kB como podemos ver nesse trecho retirado do código fonte:
/*
* workMem is forced to be at least 64KB, the current minimum valid value
* for the work_mem GUC. This is a defense against parallel sort callers
* that divide out memory among many workers in a way that leaves each
* with very little memory.
*/
state->allowedMem = Max(workMem, 64) * (int64) 1024;
E em seguida analisar o output do EXPLAIN:
BEGIN; -- 1. Iniciando uma transação.
SET LOCAL work_mem = '64kB'; -- 2. Alterando o valor de work_mem a nível de transação, outras transações na mesma sessão utilizará o valor default ou pré configurado.
SHOW work_mem; -- 3. Mostra o valor atualizado da configuração work_mem.
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS) -- 4. Explain incluindo opções que ajudam a identificar gargalos, para mais informações olhe a seção de referências.
SELECT
p.player_id,
SUM(ps.goals + ps.assists) AS total_score
FROM
player_stats ps
INNER JOIN
players p ON p.player_id = ps.player_id
GROUP BY
p.player_id
ORDER BY
total_score DESC
LIMIT 2000;
COMMIT; -- 5. Aqui poderia ser um ROLLBACK, possibilitando analisar queries de INSERT, UPDATE e DELETE.
Resultado do explain em plain text:
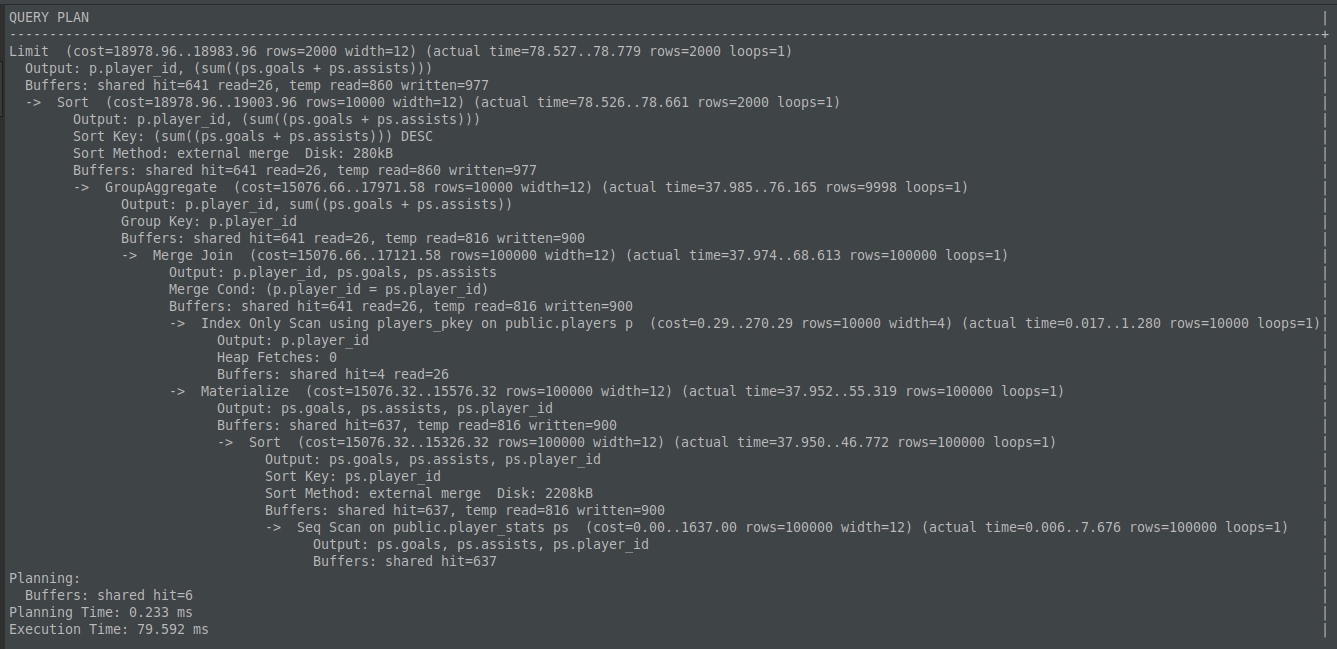
Podemos ver que o tempo de execução da query foi de 79.592ms e que o algoritmo de Sort utilizado foi o external merge, que usa disco em vez de memória dado que o conjunto de dados ultrapassou o 64kB de work_mem configurado.
Por curiosidade, o módulo tuplesort.c marca que o algoritmo de Sort irá utilizar disco setando o estado para SORTEDONTAPE nessa linha e as iterações com o disco é exposto pelo módulo logtape.c.
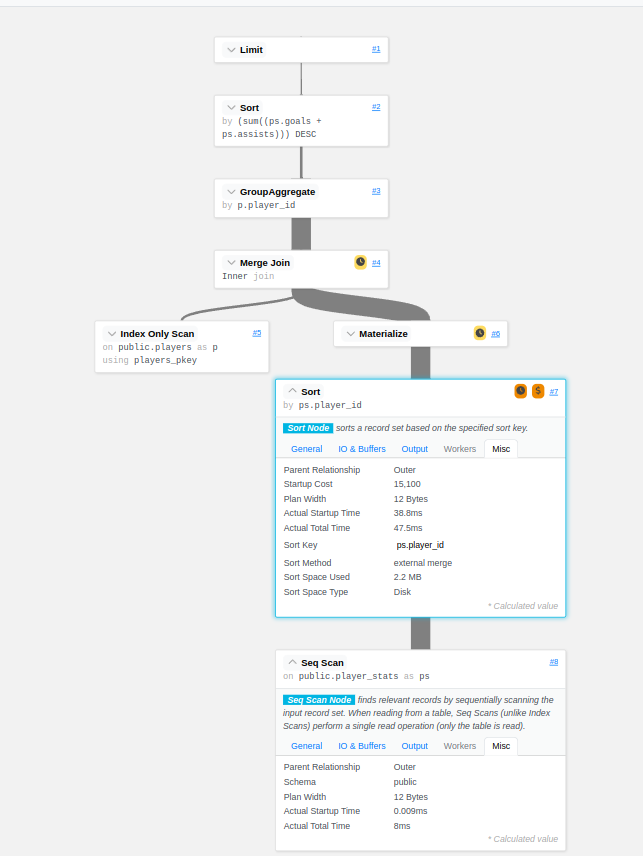
Se você é uma pessoa mais visual (como eu) existem ferramentas que facilitam o entendimento do output do EXPLAIN como https://explain.dalibo.com/, a imagem a seguir mostra um dos nós com a etapa de Sort incluindo detalhes como Sort Method: external merge e Sort Space Used: 2.2MB:
A parte de "Stats" é super útil para queries mais complexas, mostrando o quanto cada nó contribuiu em tempo de execução da query, no nosso exemplo, ele já indicaria um potencial suspeito de nós do tipo Sort que juntos levaram cerca de 42ms:
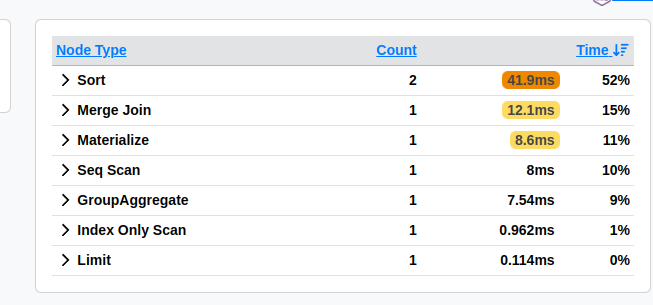
- Você pode analisar e visualizar o explain dessa query no link: https://explain.dalibo.com/plan/2gd0a8c8fab6a532#stats
Como indicado pelo EXPLAIN um dos principais problemas de performance nessa query é o nó de Sort que está utilizando disco, inclusive, um efeito colateral que pode ser observado, principalmente se você trabalhar com sistemas que possui uma quantidade considerável de usuários, é picos na métrica de Write I/O (espero que você tenha métricas, caso contrário, sinta-se abraçado), e sim, a query de leitura pode causar spikes de escrita já que o algoritmo de Sort escreve em arquivos temporários.
Solução
Se executarmos a mesma query setando work_mem=4MB(que é o default do postgres), o tempo de execução cai aproximadamente pela metade:
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS)
SELECT
p.player_id,
SUM(ps.goals + ps.assists) AS total_score
FROM
player_stats ps
INNER JOIN
players p ON p.player_id = ps.player_id
GROUP BY
p.player_id
ORDER BY
total_score DESC
LIMIT 2000;
Resultado do explain em plain text:
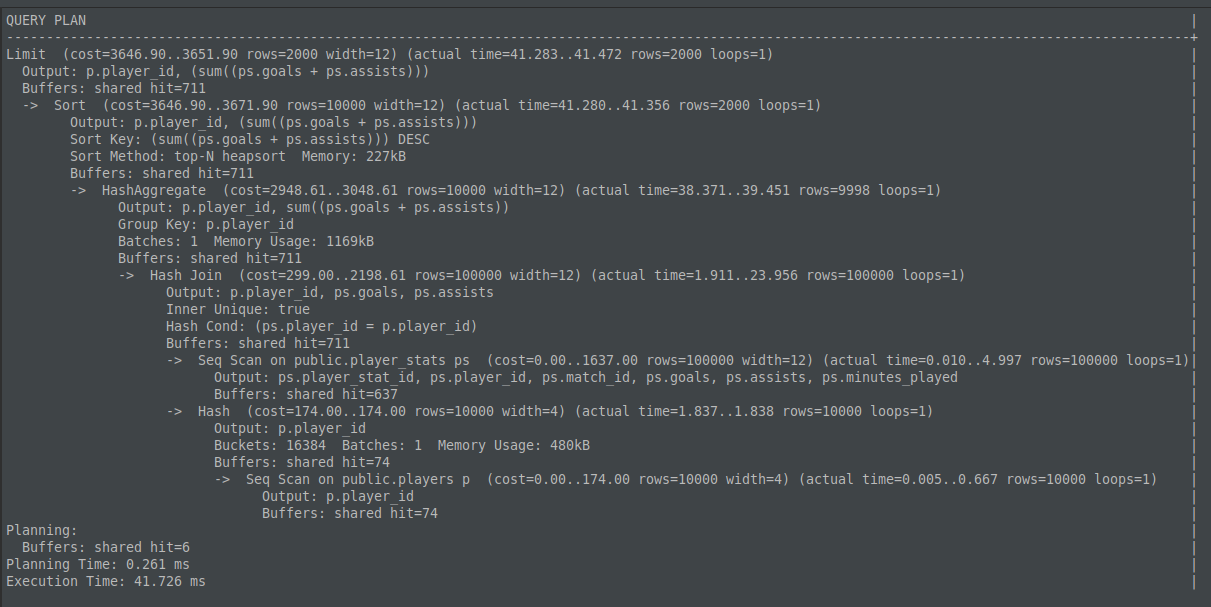
- Se preferir uma análise visual: https://explain.dalibo.com/plan/b094ec2f1cfg44f6#
Perceba que nesse explain, um dos nós de Sort passou a utilizar um algoritmo que faz sort em memória heapsort, e por curiosidade, o planner decide por um heapsort somente se achar barato o suficiente em vez de mandar um quicksort, mais detalhes no código fonte.
Além disso, o segundo nó de Sort que tomava mais tempo, aprox. 40ms simplesmente desapareceu do plano de execução da query, isso aconteceu porque o planner elencou um nó de HashJoin em vez de MergeJoin dado que agora a operação de hash cabe tranquilamente em memória, utilizando 480kB.
Mais detalhes sobre os algoritmos de join nesses artigos:
Impacto na API
Nem sempre o work_mem default será o suficiente para atender ao workload do seu sistema. Podemos simplesmente alterar esse valor a nível de usuário com:
ALTER USER foo SET work_mem='32MB';
Nota: Se você usa um pool de conexões na aplicação ou se conecta ao banco através de um pooler, é importante reciclar as sessões antigas para que a nova configuração tenha efeito.
Também podemos controlar essa configuração a nível de transação no banco. Vamos subir uma API simples para entender e mensurar o impacto com um teste de carga usando o k6:
-
k6-test.jsimport http from 'k6/http'; import { check } from 'k6'; const BASE_URL = __ENV.BASE_URL || 'http://localhost:8080'; const ENDPOINT = __ENV.ENDPOINT || '/low-work-mem'; export const options = { stages: [ { duration: '15s', target: 10 }, // ramp up to 10 users { duration: '15s', target: 10 }, { duration: '15s', target: 0 }, // ramp down to 0 users ], }; export default function () { const res = http.get(`${BASE_URL}${ENDPOINT}`); check(res, { 'status is 200': (r) => r.status === 200 }); }
A API foi implementada em golang e simplesmente expõem dois endpoints que executa a query com diferentes configurações de work_mem:
-
main.gopackage main import ( "context" "fmt" "log" "net/http" "os" "github.com/jackc/pgx/v5/pgxpool" ) func main() { ctx := context.Background() dbURL := os.Getenv("POSTGRES_URL") if dbURL == "" { dbURL = "postgres://local:local@localhost:5432/local?pool_max_conns=100&pool_min_conns=10" } pgx, err := pgxpool.New(ctx, dbURL) if err != nil { log.Fatalf("Unable to connect to database: %s", err) } defer pgx.Close() top_players_query := ` SELECT p.player_id, SUM(ps.goals + ps.assists) AS total_score FROM player_stats ps JOIN players p ON ps.player_id = p.player_id GROUP BY p.player_id ORDER BY total_score DESC LIMIT 2000; ` http.HandleFunc("/optimized-work-mem", func(w http.ResponseWriter, r *http.Request) { _, err := pgx.Exec(ctx, top_players_query) if err != nil { http.Error(w, fmt.Sprintf("Query error: %v", err), http.StatusInternalServerError) return } log.Println("Successfully executed query with work_mem=4MB") w.WriteHeader(http.StatusOK) }) http.HandleFunc("/low-work-mem", func(w http.ResponseWriter, r *http.Request) { query := fmt.Sprintf(` BEGIN; SET LOCAL work_mem = '64kB'; %s COMMIT; `, top_players_query) _, err := pgx.Exec(ctx, query) if err != nil { http.Error(w, fmt.Sprintf("Query error: %v", err), http.StatusInternalServerError) return } log.Println("Successfully executed query with work_mem=64kB") w.WriteHeader(http.StatusOK) }) log.Println("Starting server on port 8082") log.Fatal(http.ListenAndServe("0.0.0.0:8082", nil)) }
O docker compose que sobe as dependências e executa o teste de carga:
-
docker-compose.yamlversion: "3.8" services: postgres: image: postgres:17 environment: POSTGRES_PASSWORD: local POSTGRES_USER: local POSTGRES_DB: local healthcheck: test: ["CMD-SHELL", "pg_isready"] interval: 10s timeout: 5s retries: 5 volumes: - ./init_data.sql:/docker-entrypoint-initdb.d/init_data.sql # Initialize the database - ./data:/var/lib/postgresql/data # Mounts the local "data" directory to the container's data directory ports: - "5432:5432" api: build: context: . dockerfile: Dockerfile.api environment: POSTGRES_URL: postgres://local:local@postgres:5432/local?pool_max_conns=100&pool_min_conns=10 ports: - "8082:8082" depends_on: - postgres k6: image: grafana/k6 entrypoint: [ "k6", "run", "/scripts/k6-test.js" ] environment: BASE_URL: http://api:8082 ENDPOINT: /low-work-mem volumes: - ./k6-test.js:/scripts/k6-test.js depends_on: - api volumes: postgres:
Podemos alternar a variável de ambiente ENDPOINT para definir o cenário a ser testado entre: /low-work-mem e /optimized-work-mem, você pode subir os testes com docker compose up --abort-on-container-exit, utilizei a versão 20.10.22 do Docker durante a escrita desse post.
-
Teste de carga
ENDPOINT: /low-work-mem-work_mem=64kB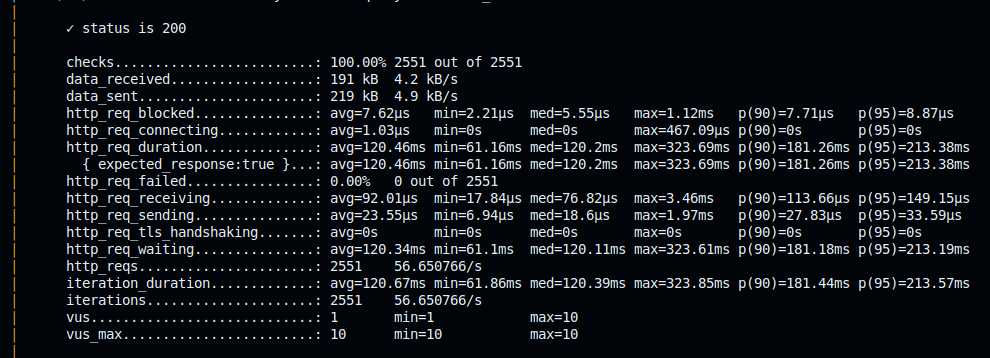
-
Teste de carga
ENDPOINT: /optimized-work-mem-work_mem=4MB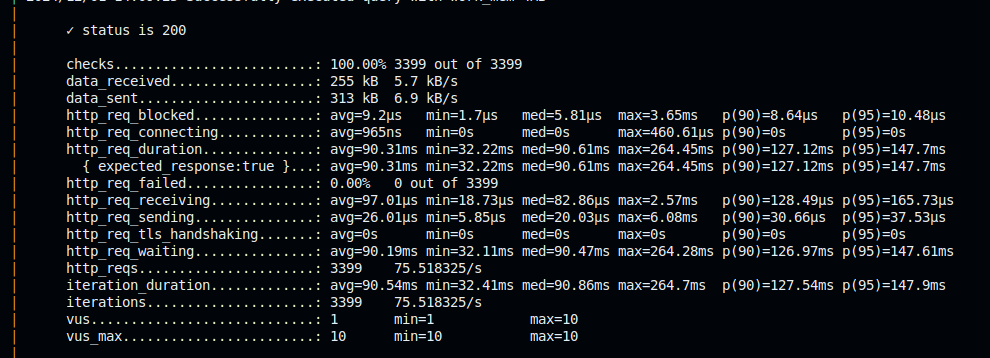
O resultado mostra que a performance do endpoint com work_mem=4MB foi bem superior ao com 64kB. O p90 diminuiu aprox 54ms e o throughput melhorou consideravelmente para o workload do teste. Se essas métricas são novas pra você, super indico estudar e entender a fundo, essas informações vão te ajudar a te guiar em análises de performance, aqui vai algumas fontes interessantes:
Conclusão
Tá, mas depois de ter sonhos com o problema, de acordar N vezes durante a noite pra tentar mais uma solução ou debug (quem nunca?) e finalmente descobrir que o work_mem pode te ajudar, como definir um valor pra esssa configuração? 😬
O valor padrão de 4MB para o work_mem, como muitas outras configurações do PostgreSQL (papo para outros posts) é conservador, não é atoa que conseguimos rodar em máquinas com pouco poder computacional, porém temos que ter cautela para não ter o risco de crashar o postgres com Running out of memory. Uma única query, se complexa o suficiente, pode usar o valor de memória de múltiplos do configurado para o work_mem, a depender do número de operações de Sort, Merge Joins, Hash Joins(work_mem multiplicado por hash_mem_multiplier) entre outras operações como destacado na documentação oficial:
it is necessary to keep this fact in mind when choosing the value. Sort operations are used for ORDER BY, DISTINCT, and merge joins. Hash tables are used in hash joins, hash-based aggregation, memoize nodes and hash-based processing of IN subqueries.
Então como nem tudo são flores, não existe uma fórmula mágica para ser aplicada cegamente, vai depender muito da memória RAM disponível, workload e padrões das queries do seu sistema. O timescaleDB possui uma ferramenta para autotune e esse assunto é bem discutido em vários artigos (excelentes por sinal) que podem te dar um norte:
Mas no fim do dia, IMHO a resposta para essa pergunta é: TESTE, TESTE HOJE, TESTE AMANHÃ, TESTE PARA SEMPRE até encontrar um valor aceitável para seu caso de uso que melhore a performance das queries do seu sistema sem explodir seu banco de dados xD
Espero que esse post tenha sido útil de alguma forma. Quando enfrentei esse problema, ainda não tinha o hábito de pesquisar in English, e a falta de conteúdo desse tipo em português acabou fazendo com que essa quest levasse mais tempo do que eu esperava. Mas confesso que foi divertido.
Pretendo trazer mais exemplos práticos com perrengues da vida real envolvendo PostgreSQL. Se tiver alguma sugestão de assunto ou crítica, deixe nos comentários! 😄
- Github com os casos de uso: https://github.com/iamseki/postgresql