Tipos de Joins no PySpark
https://www.lucasmantuan.com.br
https://github.com/lucasmantuan
https://www.linkedin.com/in/lucasmantuan
Joins são operações fundamentais para combinar dados de múltiplas fontes. O PySpark oferece diferentes tipos de joins, como inner e cross joins, outer joins (left, right, full), além de left semi e left anti joins. A sintaxe do join no PySpark é:
df1.join(df2, condição, tipo)
Inner Join
Em um Inner Join entre 2 dataframes (chamados A e B), a operação faz a correspondência de cada linha de A com cada linha de B onde a condição de join é verdadeira. Somente as linhas correspondentes de ambos os dataframes são incluídos no resultado.
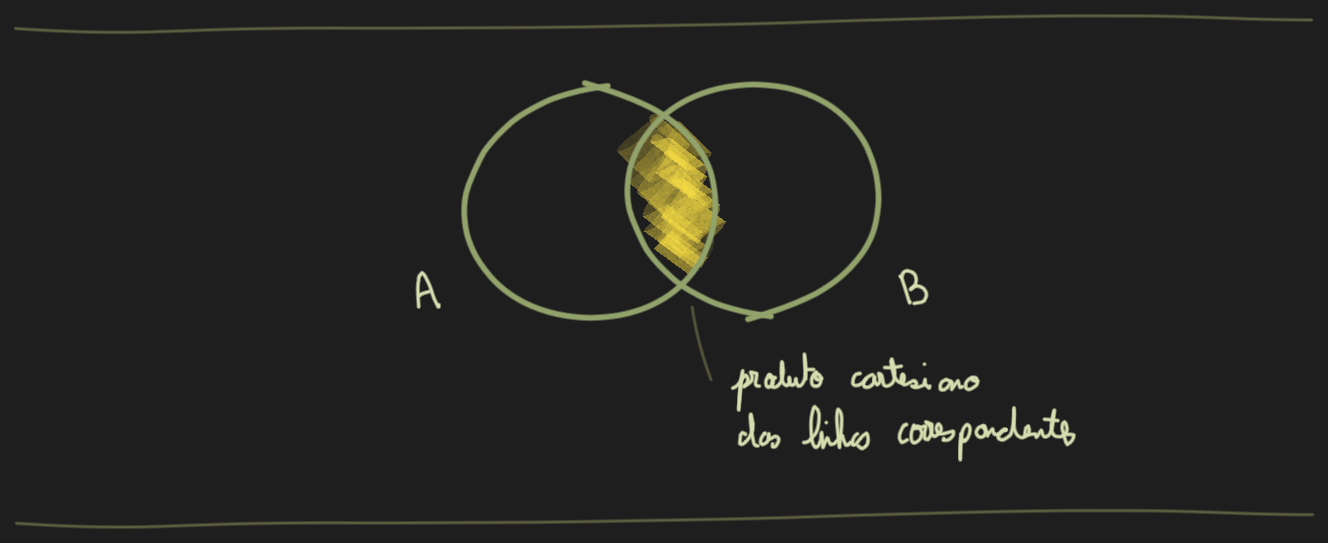
Neste exemplo queremos corresponder os funcionários com seus respectivos departamentos com base no dept_id comum entre eles, ou seja, termos uma visão combinada dos funcionários e seus nomes de departamentos.
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina |
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
| emp_id | emp_name | dept_id | dept_name |
|---|---|---|---|
| 1 | John | 1 | HR |
| 2 | Emma | 2 | Tech |
As linhas com valores null em dept_id são excluídos do resultado pois null não correspondem a nenhum valor, incluindo outros null. Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id)
SELECT *
FROM employees e
INNER JOIN departments d
ON e.dept_id = d.dept_id;
Cross Join
Um Cross Join é uma operação de join que retorna o produto cartesiano de 2 dataframes. Em outras palavras ele combina cada linha do dataframe A com cada do dataframe B, resultando em um grande conjunto de resultados não filtrados.
No Cross Join não há uma condição, pois ele simplesmente gera todas as combinações possíveis. Por isso deve ser usado com cautela, pois gera um número massivo de linhas.
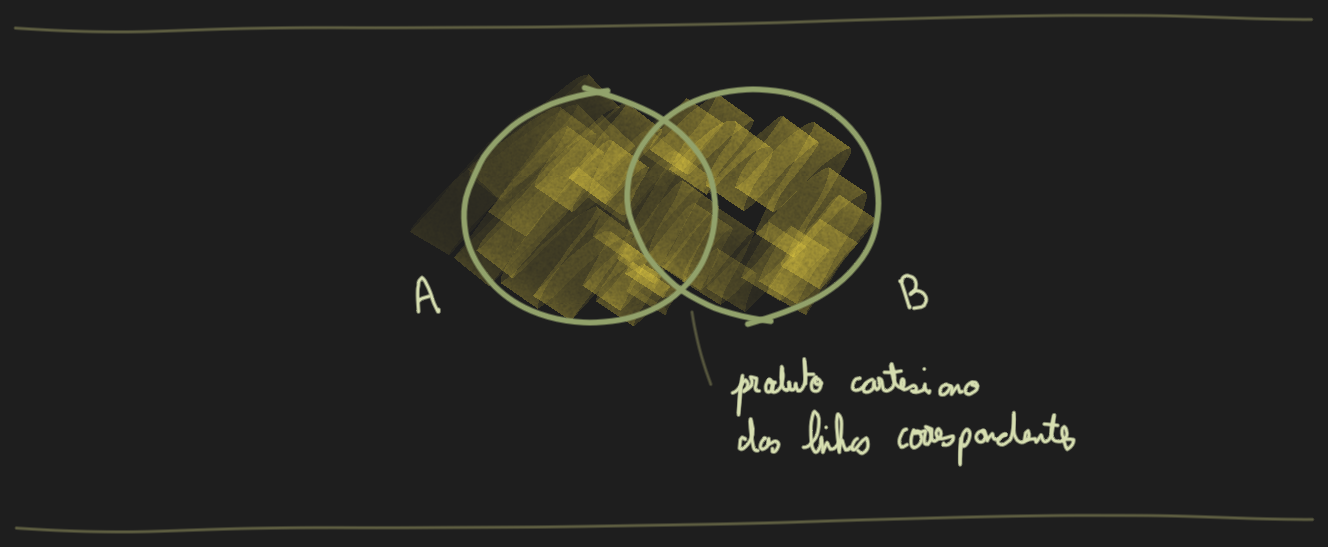
Neste exemplo queremos gerar um produto cartesiano de funcionários e departamentos, criando um resultado que parei cada funcionário com cada departamento.
| emp_id | emp_name |
|---|---|
| 1 | John |
| 2 | Emma |
| 3 | Raj |
| dept_id | dept_name |
|---|---|
| A | HR |
| B | Tech |
| emp_id | emp_name | dept_id | dept_name |
|---|---|---|---|
| 1 | John | A | HR |
| 1 | John | B | Tech |
| 2 | Emma | A | HR |
| 2 | Emma | B | Tech |
| 3 | Raj | A | HR |
| 3 | Raj | B | Tech |
Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_cross_joined = df_employees.crossJoin(df_departments)
SELECT *
FROM employees e
CROSS JOIN departments d;
Left Outer Join
Um Left Outer Join (também chamado de Left Join) entre 2 dataframes A e B, a operação encontra primeiro todas as linhas do dataframe A e, em seguida, tenta corresponder com cada linha de A com as linhas de B onde a condição de join é verdadeira.
Então, todas as linhas do dataframe A são incluídas no resultado e somente as linhas do dataframe B que correspondem à condição do join são incluídas. Não havendo correspondência, valores null são usados para preencher as colunas do dataframe B.
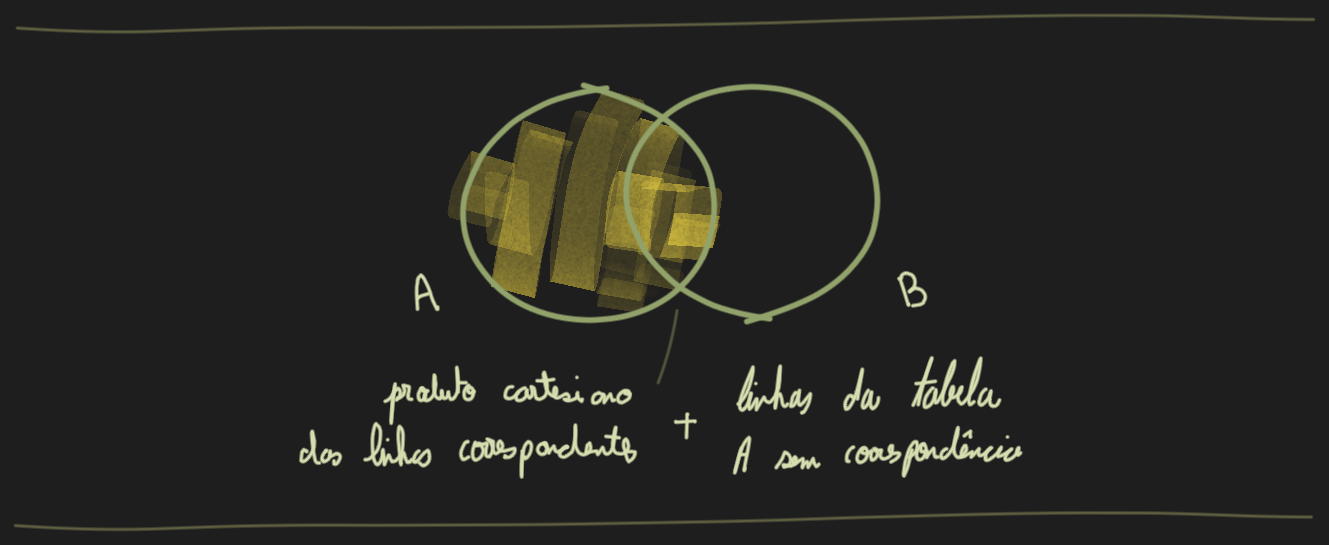
Neste exemplo, queremos corresponder os funcionários com seus respectivos departamentos com base em dept_id comum. O resultado esperado deve fornecer uma visão combinada dos funcionários e seus nomes de departamentos, incluindo aqueles funcionários com dept_id nulo.
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina | 4 |
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
| emp_id | emp_name | dept_id | dept_id | dept_name |
|---|---|---|---|---|
| 1 | John | 1 | 1 | HR |
| 2 | Emma | 2 | 2 | Tech |
| 3 | Raj | null | null | null |
| 4 | Nina | 4 | null | null |
Como você viu no exemplo, null em dept_id não corresponde a null no DataFrame B. Portanto, essas linhas não são correspondidas, e valores null são usados para preencher as colunas do DataFrame da B (linha 4). Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id, "left")
SELECT *
FROM employees e
LEFT JOIN departments d
ON e.dept_id = d.dept_id;
Right Outer Join
Um Right Outer Join (também chamado de Right Join) entre 2 dataframes A e B, a operação encontra primeiro todas as linhas do dataframe B e, em seguida, tenta corresponder com cada linha de B com as linhas de A onde a condição de join é verdadeira. É idêntico ao Left Outer Join, exceto que começa com o dataframe B em vez do dataframe A. Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id, "right")
SELECT *
FROM employees e
RIGHT JOIN departments d
ON e.dept_id = d.dept_id;
Full Outer Join
Em um Full Outer Join (também conhecido como Full Join) a operação combina os resultados dos Joins Left e Right Outer. Este tipo de join mescla as linhas de 2 dataframes A e B com base em uma condição de join. Diferente dos Joins Left ou Right, que priorizam um dataframe, o Full Outer Join trata ambos os lados de forma igual.
Ou seja, todas as linhas do dataframe A e do dataframe B são incluídas no resultado. Havendo uma correspondência entre os dataframes, com base na condição de join, as linhas são combinadas em uma única linha no resultado. Não havendo a correspondência, haverá valores nulos para as colunas do dataframe A ou B. Em termos simples, Full Outer Join = Left Outer Join + Right Outer Join.
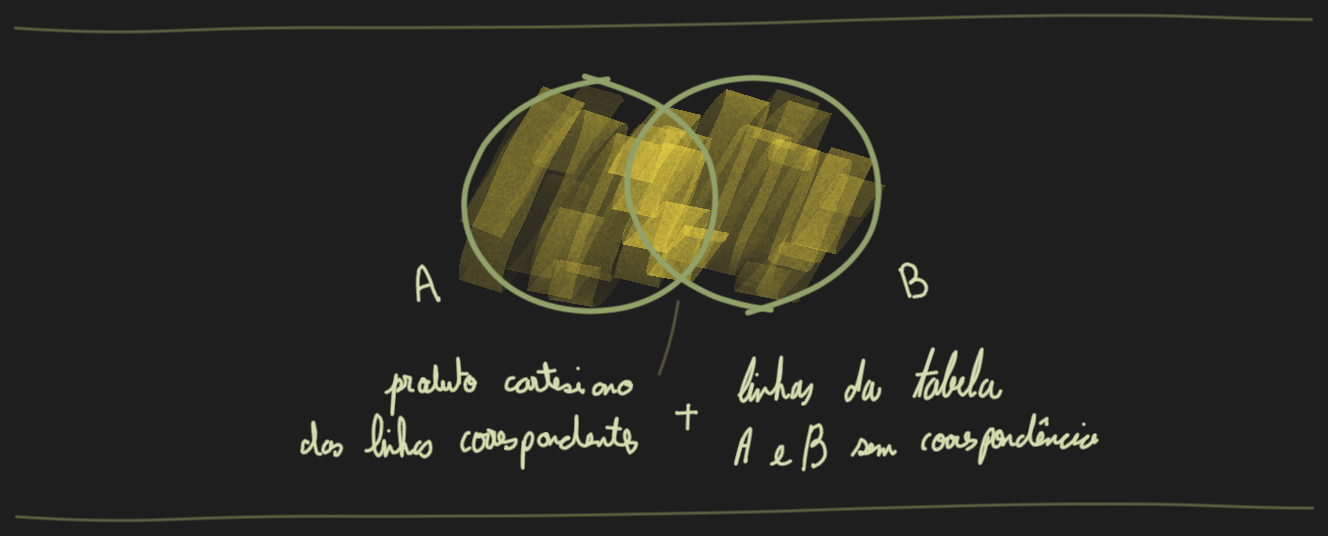
Neste exemplo, o objetivo é corresponder os funcionários com seus respectivos departamentos com base em dept_idcomum, fornecendo uma visão combinada dos funcionários e de seus departamentos, incluindo linhas sem correspondência de ambos os dataframes.
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina | 4 |
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
| emp_id | emp_name | dept_id | dept_id | dept_name |
|---|---|---|---|---|
| 1 | John | 1 | 1 | HR |
| 2 | Emma | 2 | 2 | Tech |
| 3 | Raj | null | null | null |
| 4 | Nina | 4 | null | null |
| null | null | null | null | Temp |
| null | null | null | 3 | Marketing |
Como observado no exemplo acima, os valores null não correspondem com outros valores null, portanto as linhas com valores null como chave de join não são correspondidas. Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id, "outer")
SELECT *
FROM employees e
FULL OUTER JOIN departments d
ON e.dept_id = d.dept_id;
Left Semi Join
O Left Semi Join é uma operação usada para filtrar um dataframe com base nas chaves presentes em outro dataframe, desta forma reduzindo um conjunto de dados mantendo apenas as linhas que tem uma correspondência com os dois conjuntos de dados.
O Left Semi Join retorna todos os dados do dataframe A que tem uma correspondência com o dataframe B (o oposto do Left Anti Join).
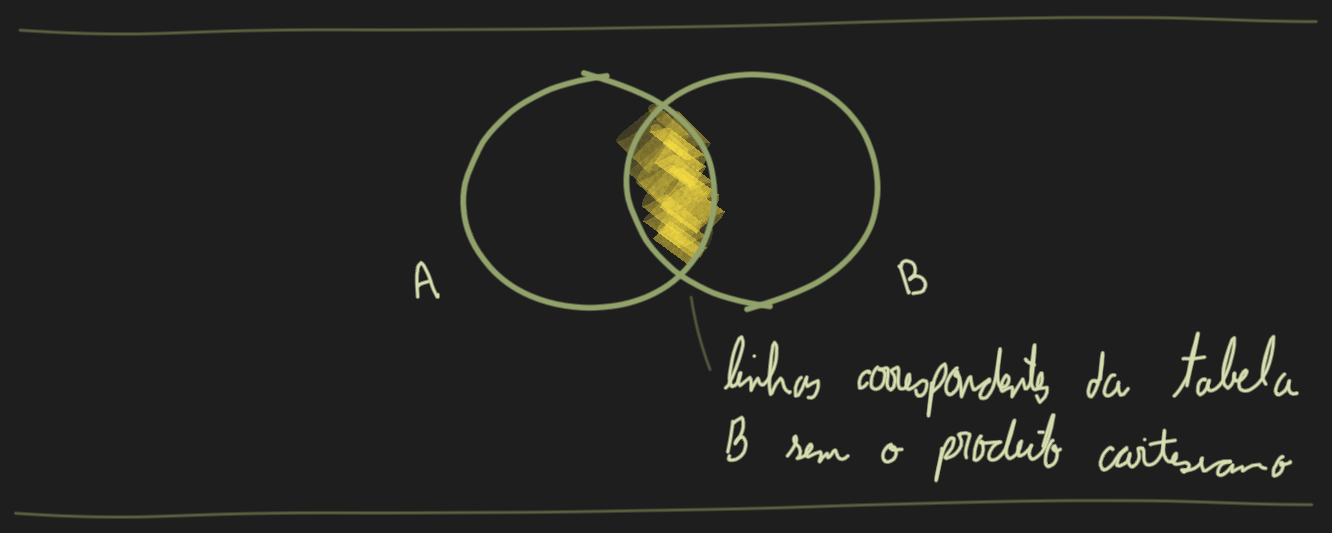
Neste exemplo queremos descobrir quais usuários fizeram compras, ou seja aqueles que aparecem nas duas tabelas. Usuários com valores null não são incluídos pois null não corresponde com outros valores null.
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | David |
| null | Eve |
| user_id | item |
|---|---|
| 1 | Book |
| 2 | Pen |
| 5 | Notebook |
| null | Pencil |
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
Left Semi Join tem como vantagem a simplicidade e o desempenho em relação a outros joins, pois só verifica a existencia das chaves sem precisar embaralhar e juntar os dados correspondentes, apesar de ser menos intuitivo para aqueles acostumados com joins SQL. Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_purchasers = df_users.join(df_purchases, df_users.id == df_purchases.user_id, "left_semi")
SELECT *
FROM users u
LEFT SEMI JOIN purchases p
ON u.id = p.user_id;
Left Anti Join
O Left Semi Join é uma ferramenta poderosa para encontrar registros não correspondentes entre dois conjuntos de dados. Retorna todas as linhas do dataframe A que não tem correspondência com o dataframe B (oposto ao Left Semi Join).
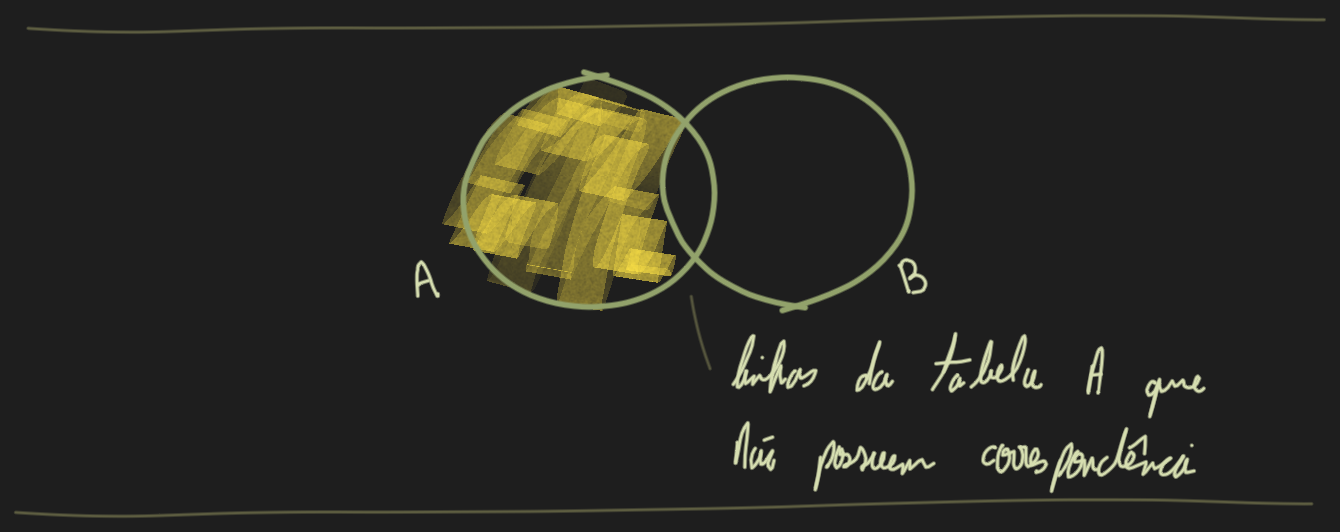
Neste exemplo queremos descobrir quais usuários não fizeram compras, ou seja aqueles onde o id não aparece na segunda tabela. O resultado também inclui os valores null, pois estes também não correspondem com outros valores null.
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | David |
| null | Eve |
| user_id | item |
|---|---|
| 1 | Book |
| 2 | Pen |
| 5 | Notebook |
| null | Pencil |
| id | name |
|---|---|
| 3 | Charlie |
| 4 | David |
| null | Eve |
Abaixo a sintaxe do PySpark e o seu equivalente no Spark SQL.
df_non_purchasers = df_users.join(df_purchases, df_users.id == df_purchases.user_id, "left_anti")
SELECT *
FROM users u
LEFT ANTI JOIN purchases p
ON u.id = p.user_id;
Otimizando Joins Para Grandes Conjuntos de Dados
Trabalhar com grandes conjuntos de dados requer algumas técnicas de otimização na realização dos join para garantir um processamento rápido e minimizar o uso de recursos. Abaixo temos algumas abordagens que pode ajudar a otimizar o join no PySpark.
- Broadcasting de dataframes menores. A função
broadcastpermite que um dataframe menor seja enviado para todos os nós do cluster, reduzindo o embaralhamento de dados durante as operações de join. Isso é especialmente útil ao juntar um dataframe pequeno com um muito maior.
from pyspark.sql.functions import broadcast
small_df = spark.createDataFrame(small)
large_df = spark.createDataFrame(large)
optimized_join = large_df.join(broadcast(small_df), on=["key"], how="inner")
- Particionamento de dataframes. Particionar os dataframes, com a função
partition, com base nas colunas que você vai usar para join pode ajudar a distribuir os dados de forma mais uniforme em seu cluster, levando a um processamento paralelo mais eficiente.
df1 = df1.repartition("key")
df2 = df2.repartition("key")
repartitioned_join = df1.join(df2, on=["key"], how="inner")
- Usando cache. Se você precisar realizar várias operações no mesmo dataframe, ou realizar várias ações no mesmo dataframe, utilize o método
cachepara persistir o dataframe na memória. ==Isso pode acelerar significativamente os tempos de processamento ao reduzir a necessidade de recalcular resultados intermediários==.
large_df.cache()
- Filtragem de dados antes do join. Para reduzir a quantidade de dados que precisam ser processados durante o join, filtre seus dados selecionando apenas as linhas relevantes com base na chave de join. Isso minimizará a quantidade de dados a serem embaralhados durante o join, levando a uma redução nos tempos de processamento.
filtered_df1 = df1.filter(df1["key"].isin(["A", "B", "C"]))
filtered_df2 = df2.filter(df2["key"].isin(["A", "B", "C"]))
filtered_join = filtered_df1.join(filtered_df2, on=["key"], how="inner")
- Utilizando a técnica de salting. Deve ser utilizada quando há desequilíbrio nas chaves de join, o que pode ocorrer quando algumas chaves têm um volume muito maior de dados do que outras. O objetivo do salting é distribuir essas chaves desbalanceadas uniformemente entre diferentes partições, evitando problemas de desempenho relacionados ao desequilíbrio.
small_df = spark.createDataFrame(small)
large_df = spark.createDataFrame(large)
salt_value = 5
large_df_salt = large_df.withColumn("salt", (rand() * salt_value).cast("int"))
small_df__salt = (small_df.withColumn("salt", lit(0)))
for i in range(1, salt_value):
small_df_with_salt = small_df_with_salt.union(small_df.withColumn("salt", lit(i)))
salted_join = large_df_with_salt.join(small_df_with_salt, on=["key", "salt"], how="inner")
Melhores Práticas no Uso de Joins
- Aplique filtros o mais cedo possível, reduzindo o tamanho dos dataFrames antes de realizar o join. Isso ajuda a minimizar o volume de dados processados nas etapas subsequentes.
- Particione seus dataFrames de forma eficaz, especialmente nas chaves de join, para reduzir o embaralhamento (shuffle) de dados entre as partições. Isso pode melhorar significativamente o desempenho.
- Certifique-se de que as colunas de chave do join têm o mesmo tipo de dado em ambos os dataFrames. Inconsistências de tipo podem causar falhas ou junções incorretas.
- Utilize o broadcast para dataFrames pequenos, o que significa enviá-los para todos os nós que contêm partições do dataFrame maior, melhorando a eficiência do join.
- Remova valores nulos nas colunas de chave do join antes de realizar a junção, para evitar resultados inesperados ou incompletos.
- Identifique se há assimetria nos seus dados, ou seja, se algumas chaves possuem um volume significativamente maior de dados que outras. Isso pode gerar desequilíbrio e impactar o desempenho.
- Ao trabalhar com dataFrames que possuem colunas de mesmo nome, renomeie essas colunas ou utilize aliases para evitar conflitos e ambiguidades no resultado final.
- Selecione apenas as colunas necessárias antes de realizar o join. Isso reduz o volume de dados transferidos e embaralhados, melhorando a eficiência da operação.
- Sempre que possível, agrupe os dados na chave de join (clustering). Esse agrupamento físico pode acelerar a execução do join, pois os dados já estarão próximos uns dos outros no armazenamento.
- Utilize técnicas como salting ou broadcasting para mitigar o impacto da assimetria nos joins, distribuindo melhor as chaves.
- Verifique a existência de chaves duplicadas, já que elas podem inflar os resultados e degradar o desempenho, causando operações desnecessárias ou incorretas.
Referências
https://iomete.com/resources/reference/pyspark/pyspark-join
https://www.cojolt.io/blog/joining-merging-data-with-pyspark-a-complete-guide