SLURM: O Gerenciamento Eficiente de Tarefas em Supercomputadores!
Introdução
Com o avanço da computação de alto desempenho (HPC), a administração eficiente de processos e recursos tornou-se essencial para o funcionamento otimizado de supercomputadores. O SLURM (Simple Linux Utility for Resource Management) é um dos principais sistemas de gerenciamento de workload, amplamente utilizado para orquestrar tarefas, alocar recursos e otimizar o uso de grandes clusters e supercomputadores. Neste artigo, exploraremos como o SLURM gerencia tarefas e processos e garante a eficiência do ambiente de supercomputação.
O que é o SLURM?
SLURM é um sistema de gerenciamento de workload open-source projetado para distribuir, agendar e monitorar tarefas em ambientes de HPC. Ele permite a alocação dinâmica de recursos, como CPUs, GPUs, memória e nós, assegurando que as tarefas sejam realizadas de forma eficiente e organizada.
Supercomputadores modernos, compostos por milhares de nós, precisam de um sistema robusto para gerenciar o fluxo de trabalho e evitar gargalos de performance. É aí que entra o SLURM, garantindo que cada tarefa receba os recursos apropriados e que o cluster funcione de forma otimizada.
Como Funciona o Gerenciamento de Tarefas e Processos
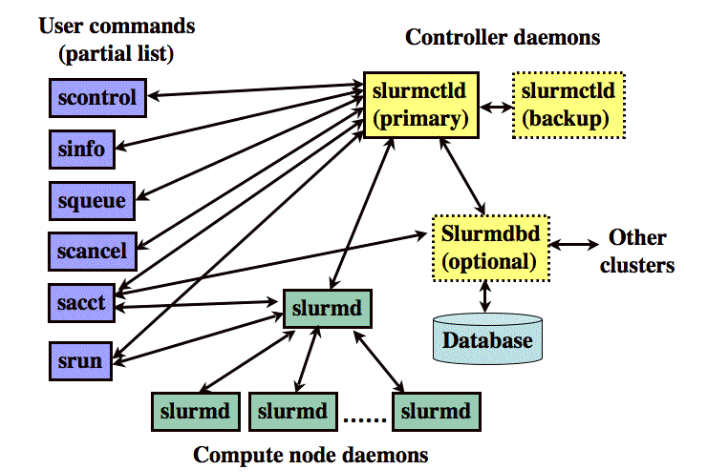
SLURM se destaca por sua arquitetura modular e por seu mecanismo distribuído de alocação de recursos e tarefas. O sistema divide-se em três componentes principais:
-
Controlador (Slurm Controller ou slurmctld)
Este é o componente principal responsável por gerenciar e monitorar o status dos recursos e tarefas no cluster. Ele recebe solicitações dos usuários, organiza as filas e decide quais tarefas serão executadas com base em políticas definidas, como prioridade e disponibilidade de recursos. -
Daemons nos Nós (Slurmd)
Cada nó de processamento executa um daemon chamado slurmd, responsável por receber, iniciar e monitorar as tarefas atribuídas a ele. Esse daemon se comunica com o controlador para garantir a execução correta dos jobs e para reportar o status das operações. -
Banco de Dados (SlurmDBD)
Esse componente armazena informações históricas e métricas das tarefas executadas. Isso é importante para a auditoria, otimização de recursos e análise de desempenho ao longo do tempo.
Políticas de Prioridade
O escalonador do SLURM oferece suporte a várias políticas de priorização, como:
- FIFO (First-In-First-Out): Jobs são executados na ordem em que são recebidos.
- Fair-Share: Recursos são distribuídos de maneira equilibrada entre os usuários.
- Backfilling: Jobs menores são executados à frente de outros maiores, se houver recursos ociosos.
Comandos
| Comando | Descrição |
|---|---|
| sinfo | Visualize as informações das partições e nós do supercomputador. |
| sprio | Visualize as informações dos fatores que compõem a prioridade na fila de cada job. |
| squeue | Visualize as informações gerais dos Job's que estão na fila ou executando. |
| sbatch | Submeta um Job para o supercomputador. |
| scancel | Cancele um Job que está na fila ou em execução. |
sinfo
sinfo exibe as informações das partições e nós do supercomputador.
Exemplo: sinfo
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cluster* up 20-00:00:0 1 down* r1i2n14
cluster* up 20-00:00:0 18 alloc r1i0n[1-2,4-7,11-12,14-16],r1i1n[7,9,15],r1i2n[1-2,11],r1i3n1
cluster* up 20-00:00:0 13 mix r1i0n[0,3,9],r1i1n[4-6,10,14],r1i2n[3-4,10,13],r1i3n2
cluster* up 20-00:00:0 19 idle r1i0n[10,17],r1i1n[0-3,11-13,16],r1i2n[0,5-7,9,12,15-16],r1i3n0
service up 20-00:00:0 3 mix service[1,3-4]
service up 20-00:00:0 1 alloc service2
test up 30:00 1 down* r1i2n14
test up 30:00 19 alloc r1i0n[1-2,4-7,11-12,14-16],r1i1n[7,9,15],r1i2n[1-2,11],r1i3n1,service2
test up 30:00 16 mix r1i0n[0,3,9],r1i1n[4-6,10,14],r1i2n[3-4,10,13],r1i3n2,service[1,3-4]
test up 30:00 19 idle r1i0n[10,17],r1i1n[0-3,11-13,16],r1i2n[0,5-7,9,12,15-16],r1i3n0
intel-512 up 20-00:00:0 6 mix r1i3n[11-16]
intel-256 up 20-00:00:0 6 mix r1i3n[3-6,9-10]
intel-256 up 20-00:00:0 1 idle r1i3n7
gpu up 2-00:00:00 2 idle gpunode[0-1]
A lista abaixo mostra o que representa cada campo de saída do comando sinfo.
-
PARTITION: Partições do supercomputador
- cluster: Partição padrão indicada pelo asterisco, composta por 64 nós
computacionais em lâmina.
r1i0n[0-7, 9-12, 14-17], r1i1n[0-7, 9-16], r1i2n[0-7, 9-16] e r1i3n[0-7,
9-16] - test: Partição para testes rápidos, composta por 72 (todos) nós
computacionais. Jobs rodados na partição teste tem o valor de prioridade
aumentado em 15000.
r1i0n[0-7, 9-12, 14-17], r1i1n[0-7, 9-16], r1i2n[0-7, 9-16], r1i3n[0-7,
9-16], service[1-4, 8-11] - service: Partição composta por 4 nós computacionais.
service[1-4] - knl: Partição composta por 2 nós computacionais com grande número de
núcleos.
service[8,9] - gpu: Partição composta por 2 nós computacionais com 8 GPUs cada.
service[10,11] - full: Partição composta por todos os 72 nós computacionais.
r1i0n[0-7, 9-12, 14-17], r1i1n[0-7, 9-16], r1i2n[0-7, 9-16], r1i3n[0-7,
9-16], service[1-4, 8-11]
Mais detalhes sobre o hardware podem ser vistos em
Hardware - cluster: Partição padrão indicada pelo asterisco, composta por 64 nós
-
AVAIL: Disponibilidade de cada partição (Available)
-
TIMELIMIT: Tempo limite de execução do job na partição correspondente.
Todas as partições possuem o tempo limite de 20 dias para execução do job.
Exceto a partição teste, cujo o tempo limite é de 30 minutos com ganho na
prioridade para execução.
Formato do timelimit no comando sinfo: Dias - horas : minutos
: segundos, exemplo: 20-13:22:21 significa 20 dias, 13 horas, 22 minutos e
21 segundos -
NODES: Número de nós de cada partição
-
STATE: Campo mais relevante dado como resposta do comando sinfo. Seu
resultado pode ter significados diferentes, dependendo da saída fornecida,
conforme é possível verificar abaixo.-
alloc: Indica que um conjunto de nós está em uso
-
idle: Indica que um conjunto de nós está ocioso
-
down/drain: Indica que um conjunto de nós se encontra indisponível
-
maint/resv: Indica que um conjunto de nós está reservados
-
mix: Indica que um conjunto de nós está sendo compartilhados por mais de
um job
-
-
NODELIST: Representa as listas de nós correspondentes a cada par
partição/estado