Como Estruturar Novos Setores em uma empresa com Algoritmos de Análise de Reuniões
Nota do Autor:
"Faz um bom tempo que não escrevo um artigo técnico por aqui, mas estou de volta para compartilhar uma experiência interessante de um projeto que desenvolvi na empresa onde trabalhei. Infelizmente, a ideia acabou sendo descartada para dar lugar a outras prioridades mais urgentes."
Contexto e Ideia do Projeto
Na empresa, que era uma startup em estágio inicial, havia poucos setores, cada um composto por uma ou duas pessoas. As reuniões eram documentadas em atas e armazenadas no Notion. No setor de dados, eu liderava a equipe, que incluía alguns estagiários. O setor ainda estava em uma fase experimental, sem um direcionamento claro sobre quais tarefas seriam prioritárias — se atuaríamos como suporte, coordenação, planejamento, ou se seríamos um setor ativo nas operações.
Foi nesse cenário que surgiu a ideia de analisar os textos das atas de reuniões usando Processamento de Linguagem Natural (NLP). Embora já existissem ferramentas como o ChatGPT capazes de fazer algo similar, decidi que seria mais interessante e desafiador desenvolver um algoritmo, utilizando Python ou JavaScript.
Estruturando a Documentação
Apesar de serem bem documentadas, as atas de reuniões não seguiam um formato padronizado. Cada pessoa escrevia de forma distinta, o que frequentemente resultava em textos confusos e difíceis de interpretar. Isso tornava o trabalho de análise mais complexo e exigia que o texto fosse reescrito em reuniões seguintes, o que não era prático.
Para resolver isso, não quisemos mudar a forma de escrita de cada pessoa, mas sim adicionar uma camada de estruturação através de identificadores, facilitando tanto a leitura quanto a análise automatizada. Foi aí que introduzimos o uso de emojis como marcadores:
Exemplo de Ata Estruturada:
15 de Julho de 2024
📋 Pautas
📊 Apresentação: Modelo de governança para projetos dev (segunda 15/7 às 17:00).
🔧 Ação: Manter ritmo e qualidade do código.
🔍 Revisão: Aprimorar o modelo atual para maior eficiência.
🗓️ Planejamento: Definir prazos detalhados para cada fase do projeto.
🗓️ Planejamento: Determinar o número ideal de desenvolvedores para atender às demandas.
A utilização de emojis funcionou como uma iconografia intuitiva, ajudando a identificar rapidamente as prioridades e o contexto de cada item discutido e, paralelamente, resolvia o problema de organização textual das atas de forma paliativa.
Escolhendo o Modelo correto - LDA e Modelagem de Tópicos
Bom, com os dados limpos e organizados, bastava escolher qual o modelo de análise estatística seria o ideal para extrair e análisar cada identificador, existem muitos modelos que são capazes de fazer isso, mas o que mais me chamou atenção foi o LDA.
A modelagem de tópicos é uma técnica de análise estatística utilizada para identificar padrões temáticos em coleções de textos. Essencialmente, o objetivo é descobrir os tópicos ocultos que estão presentes nos documentos, agrupando palavras que aparecem frequentemente juntas. Essa abordagem permite que possamos "resumir" uma grande quantidade de texto, facilitando a compreensão do seu conteúdo e permitindo a extração de insights.
No contexto do projeto, a modelagem de tópicos é extremamente útil porque nos permite analisar o conteúdo das atas de reuniões de forma automatizada, identificando os principais temas e direcionamentos discutidos. Considerando que o setor ainda estava em fase de formação e não tinha um foco claro, a modelagem de tópicos ajudou a responder perguntas como:
- Quais são os tópicos mais discutidos nas reuniões?
- O setor está mais focado em planejamento, execução técnica ou suporte?
- Quais são as áreas prioritárias e que precisam de mais atenção?
LDA (Latent Dirichlet Allocation): O Modelo Escolhido
Entre os diferentes modelos de modelagem de tópicos, optei por utilizar o LDA (Latent Dirichlet Allocation), uma das técnicas mais populares e eficazes. O LDA é um modelo generativo probabilístico que assume que cada documento é uma mistura de vários tópicos, e que cada tópico é composto por uma distribuição de palavras. Em outras palavras, o LDA tenta responder à pergunta: quais são os tópicos que melhor explicam o conjunto de documentos analisado?
Como o LDA Funciona
O LDA (Latent Dirichlet Allocation) é um modelo probabilístico generativo que busca identificar tópicos ocultos em um conjunto de documentos de texto. Ele parte da premissa de que cada documento é uma mistura de tópicos e que cada tópico é composto por uma distribuição de palavras.
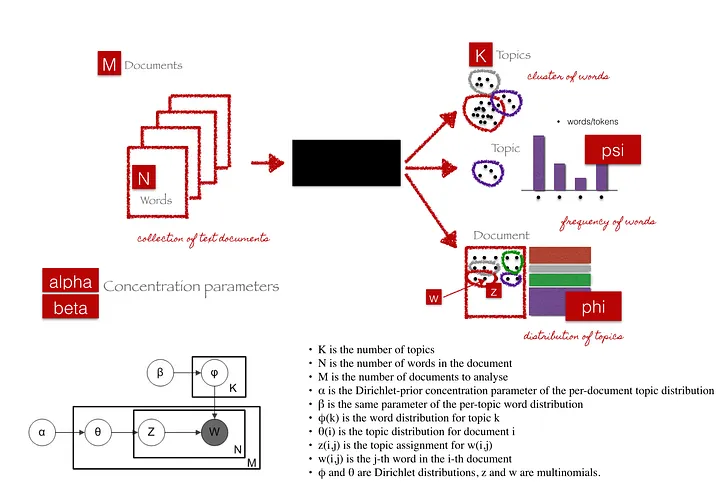
Exemplo: Imagine que você tem uma coleção de artigos de notícias. Um artigo específico pode conter 60% de um tópico sobre "política" e 40% sobre "economia". Cada um desses tópicos é representado por palavras características, como "eleição", "governo" e "orçamento".
Como o LDA Gera Documentos
Para entender como o LDA funciona, vou simplificar o processo em três etapas:
-
Seleção de Tópicos para o Documento: O LDA começa escolhendo uma distribuição de tópicos para cada documento. Por exemplo, um documento pode ser 70% sobre "tecnologia" e 30% sobre "negócios".
-
Escolha do Tópico para Cada Palavra: Para cada palavra do documento, o LDA seleciona aleatoriamente um tópico com base na distribuição definida. Ou seja, ele decide qual tópico a palavra vai representar.
-
Geração da Palavra: A partir do tópico escolhido, o LDA seleciona uma palavra que seja característica desse tópico. Por exemplo, se o tópico for "esportes", o modelo pode escolher palavras como "jogo", "time" ou "campeonato".
Essas três etapas são repetidas para cada palavra de cada documento, gerando a coleção completa de textos.
Contabilização, visualização e importancia dos dados extraidos
Após a etapa de extração e organização dos textos em tópicos, chega o momento de contabilizar e visualizar esses dados para obter insights práticos. Para qualquer projeto que envolva análise de texto, especialmente em um contexto corporativo, ter uma estrutura de indicadores bem definida é essencial. Eles nos ajudam a entender a dinâmica do setor e a responder a perguntas críticas, como:
- Quais tipos de ação são mais solicitados?
- Quais atividades são executadas com maior frequência?
- Quais são os termos, nomes ou projetos mais mencionados nas reuniões?
Para a estratégia esses dados podem servir para casos de usos interessante desde entender funcionamento e dinamica do setor até mesmo para poder identificar a carga de trabalho colocada em cada membro da equipe.