Cientistas usam dinâmica de fluidos para detectar deepfakes em áudio
Pesquisadores da Universidade da Flórida desenvolveram uma técnica que permite medir as diferenças acústicas e de dinâmicas de fluidos entre amostras de voz criadas organicamente por falantes humanos e aquelas geradas sinteticamente por computadores.
Segundo os cientistas, o primeiro passo para diferenciar esses dois tipos de fala é entender como modelar acusticamente o trato vocal.
Humanos vocalizam forçando o ar por entre as várias estruturas do trato vocal. A fala acontece porque, ao reorganizar essas estruturas, é possível alterar suas propriedades acústicas, permitindo criar mais de 200 sons ou fonemas distintos.
As deepfakes, por outro lado, são geradas por meio de amostras de áudio do falante original e algoritmos de conversão de texto em fala. Algo completamente diferente.
A ciência já tem técnicas para estimar como alguém soaria com base em medidas anatômicas de seu trato vocal. Ao inverter muitas dessas técnicas, a equipe conseguiu extrair uma aproximação do trato vocal de um falante durante um segmento da fala - o que tornou possível examinar efetivamente a anatomia da pessoa (ou máquina) que criou a amostra de áudio.
A hipótese levantada era de que as amostras de áudio deepfake não seriam restringidas pelas mesmas limitações anatômicas que os humanos têm, o que resultaria em simulações de formatos de trato vocal que não existiriam em pessoas de verdade.
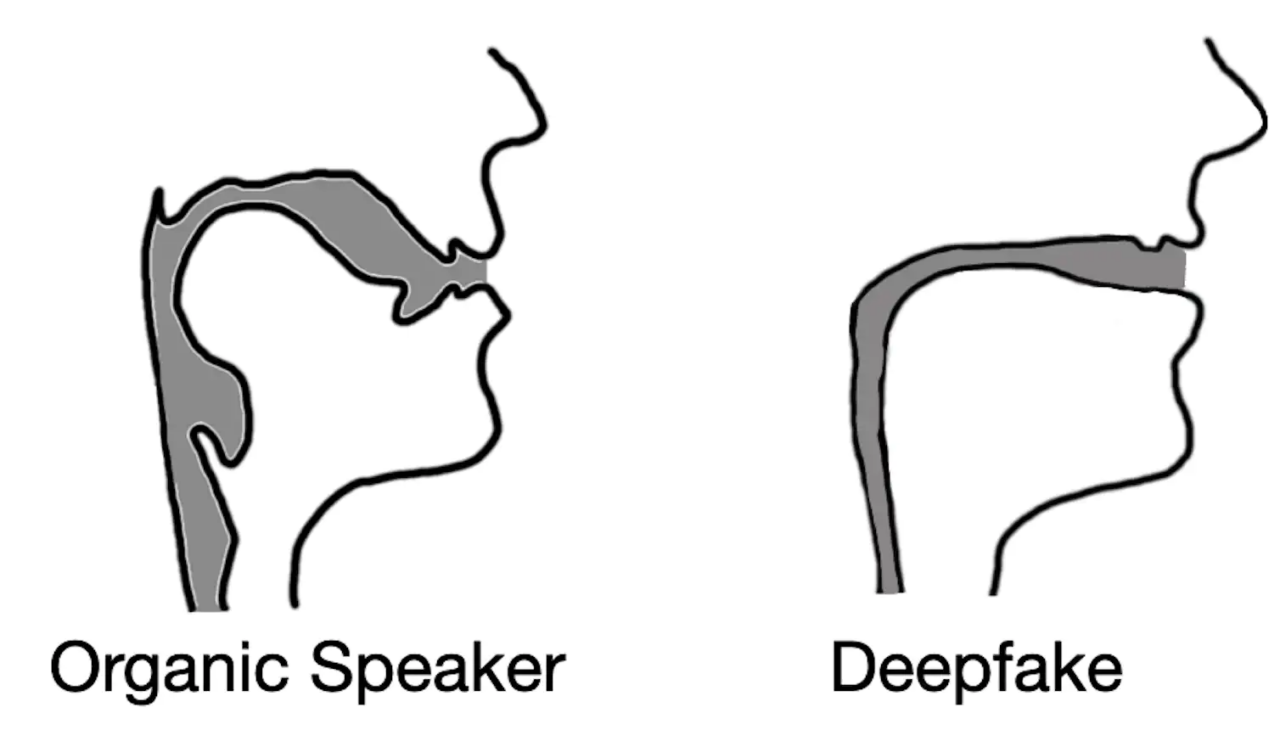
Áudios deepfake geralmente resultam em reconstruções de trato vocal que se assemelham a canudos em vez de tratos vocais biológicos.
Os resultados obtidos confirmaram isso. Por exemplo, era comum que um áudio deepfake resultasse em tratos vocais com um diâmetro e consistência semelhantes a um canudo - tratos vocais humanos são muito mais amplos e em formatos variados.
Essa percepção demonstra que áudios deepfake, mesmo quando convincente para nossos ouvidos, estão longe de ser indistinguíveis da fala gerada por humanos.