Conheça esta técnica avançada de NodeJS
Em cenários aonde o throughput é muito alto, a solução mais comumente utilizada é adicionar uma camada de caching, seja no client side para os assets, seja no backend para os dados.
No entanto, existe uma combinação de duas técnicas que pode ser usada de forma isolada em recursos com alto throughput, que aplica um nível mais básico de caching e que a depender do cenário, pode reduzir o tempo de resposta das requisições.
Esta combinação de técnicas se chama: Asynchronous Request Batching and Caching, que consiste em resolver as requisições em lotes e fazer cache em memória dos resultados.
Para explicar como ela funciona, vou ilustrar como geralmente são os fluxos de requisição, e em seguida, vou apresentar uma variação da ilustração aplicando a técnica de batching acompanhada do código, e em seguida, farei o mesmo aplicando a combinação do cache em memória.
Duas requisições assíncronas (sem as técnicas)
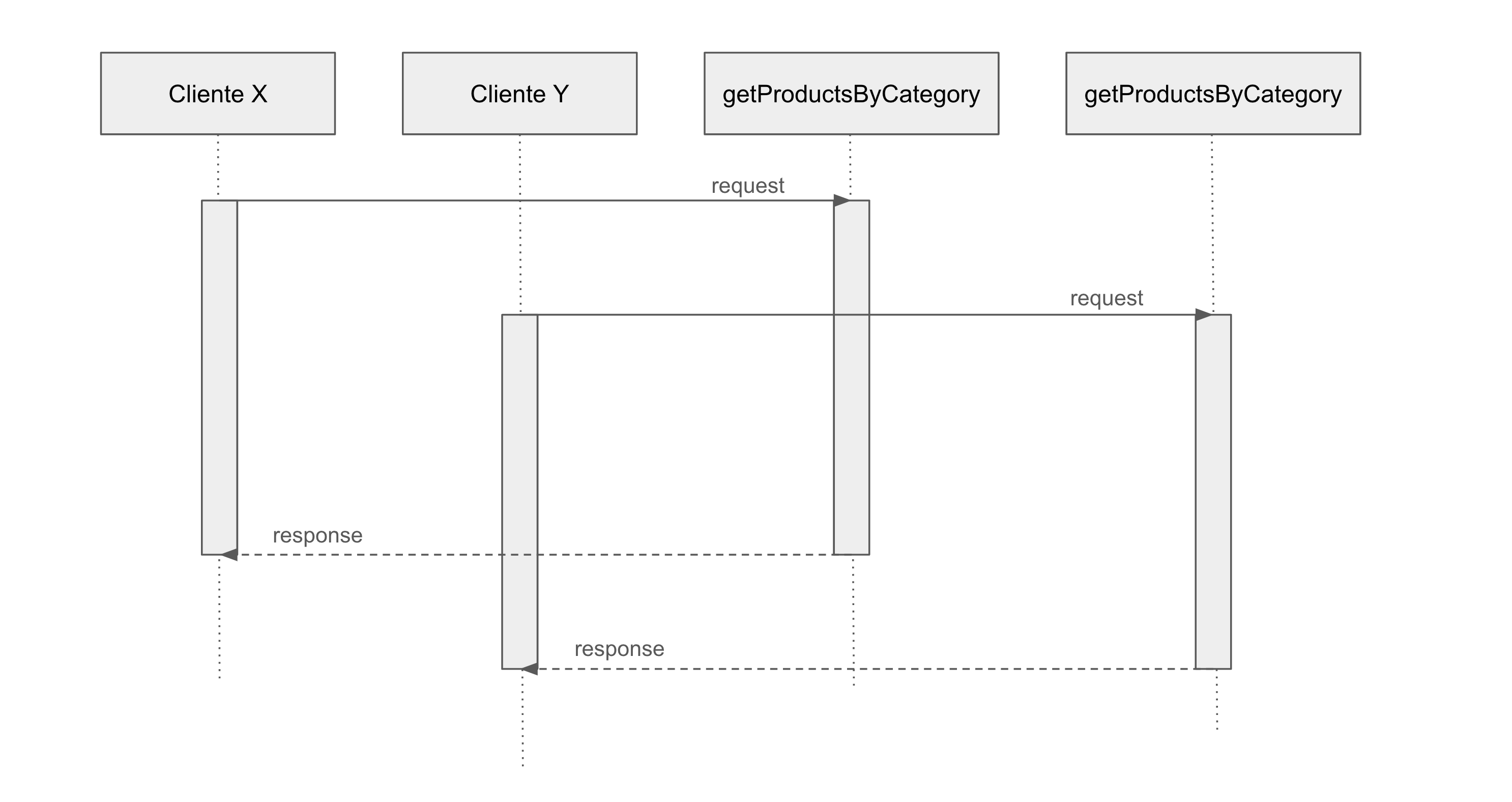
Observe que cada requisição invoca a função de getProductsByCategory e cria um fluxo individual de requisição e resposta. Então, a consulta no banco de dados será replicada para cada uma das requisições.
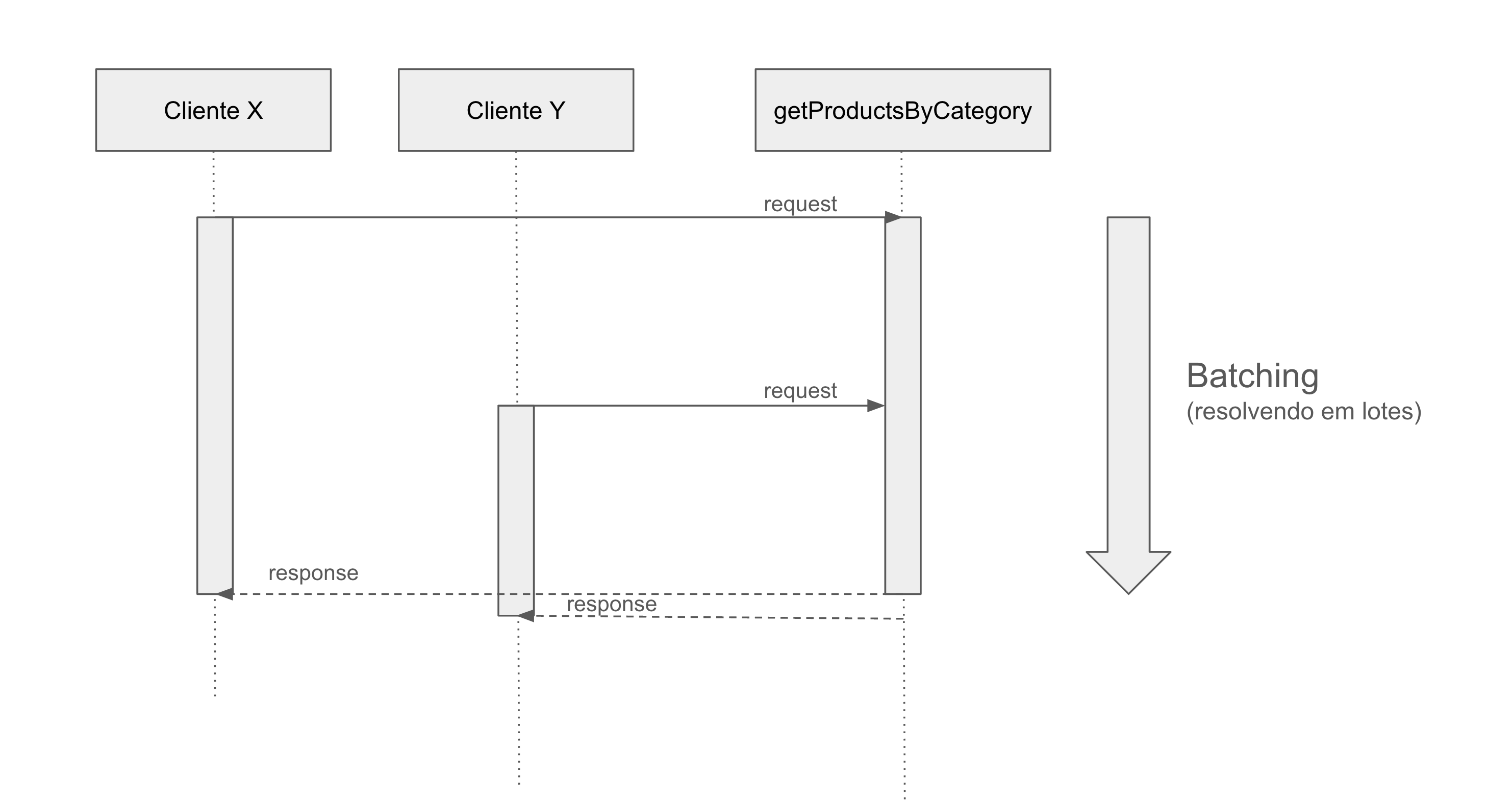
Agora, veja o que acontece quando aplicamos a técnica de requisições em lote (batching).
Aplicando a técnica de Requisições em Lote (batching)
Implementação da técnica
import getProductsByCategoryRaw from "./getProductsByCategoryRaw.js"
const requestsBatch = new Map()
async function getProductsByCategory(category) {
if (requestsBatch.has(category)) {
return requestsBatch.get(category)
}
const result = getProductsByCategoryRaw(category)
requestsBatch.set(category, result)
result.finally(()=>{
requestsBatch.delete(category)
})
return result
}
export default getProductsByCategory
Veja que a função getProductsByCategoryRaw (que de fato faz a consulta no banco) retorna uma Promise. Salvamos a Promise em um Map utilizando como chave a própria categoria do produto, e isso garante que as requisições seguintes terão acesso à mesma Promise que ainda não foi resolvida. Quando ela for resolvida, retornará o mesmo resultado para todas as requisições do lote, e o finally vai remover a Promise do mapa.
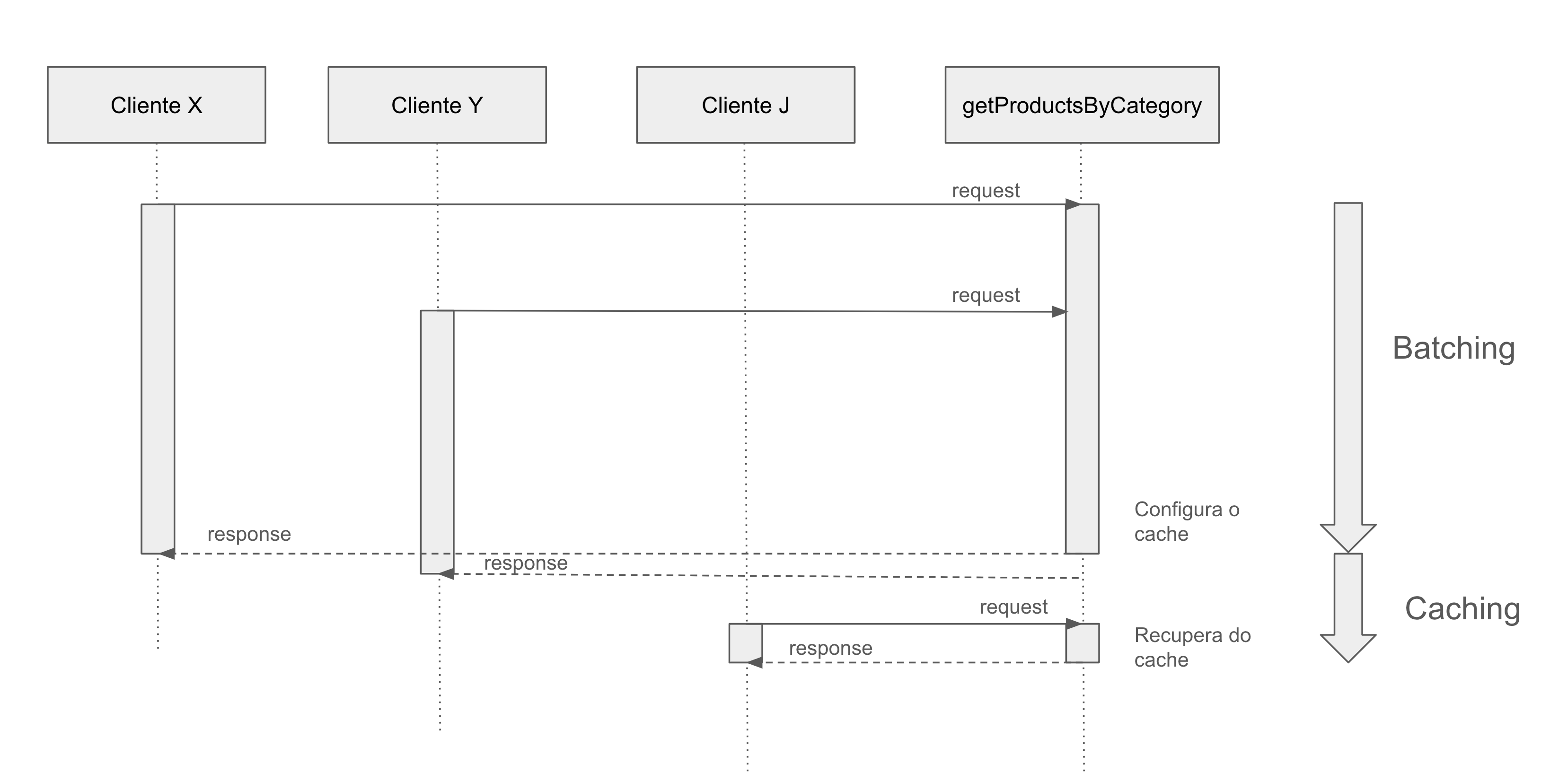
Combinando batching com caching
Implementação da técnica
import getProductsByCategoryRaw from "./getProductsByCategoryRaw.js"
const CACHE_TTL = 30 * 1000
const cache = new Map()
async function getProductsByCategory(category) {
if (cache.has(category)) {
return cache.get(category)
}
const result = getProductsByCategoryRaw(category)
cache.set(category, result)
result.then(() => {
setTimeout(() => {
cache.delete(category)
}, CACHE_TTL)
}, err => {
cache.delete(category)
throw err
})
return result
}
export default getProductsByCategory
Comparando com o exemplo anterior, a lógica é bem parecida, porém, ao invés de imediatamente remover a Promise resolvida do mapa, mantemos ela em memória por um tempo de vida (que no caso do exemplo foi de 30 segundos). O que significa que as requisições que acontecerem no período de agrupamento do lote, terão acesso ao resultado final quase que ao mesmo tempo (assim como no exemplo anterior, aplicando apenas o batching), e durante os 30 segundos seguintes à resolução da Promise, toda requisição terá retorno quase que imediato, pois a Promise já está resolvida no cache.
Isso é possível, porque Promises no javascript permitem acesso à seu resultado mesmo após serem resolvidas. E as técnicas acima tiram proveito disso.
Ressalvas
As técnicas que apresentei não são "bala de prata" e a estratégia de caching que apresentei é muito simples, e exige memória. Sobretudo, ela faz sentido em cenários aonde você possui uma alta taxa de transferência (throughput) em um curto espaço de tempo. Se você tiver um volume alto de requisições, mas que possuem uma distância temporal, certamente as técnicas não ajudarão em nada, e pode ser que uma camada de cache tradicional seja mais pertinente. Sempre procure entender o cenário do seu problema com métricas e análises delas.
Bons estudos e um forte abraço!