Modelo de linguagem de código aberto supera GPT-4 Turbo em problemas de codificação pela primeira vez
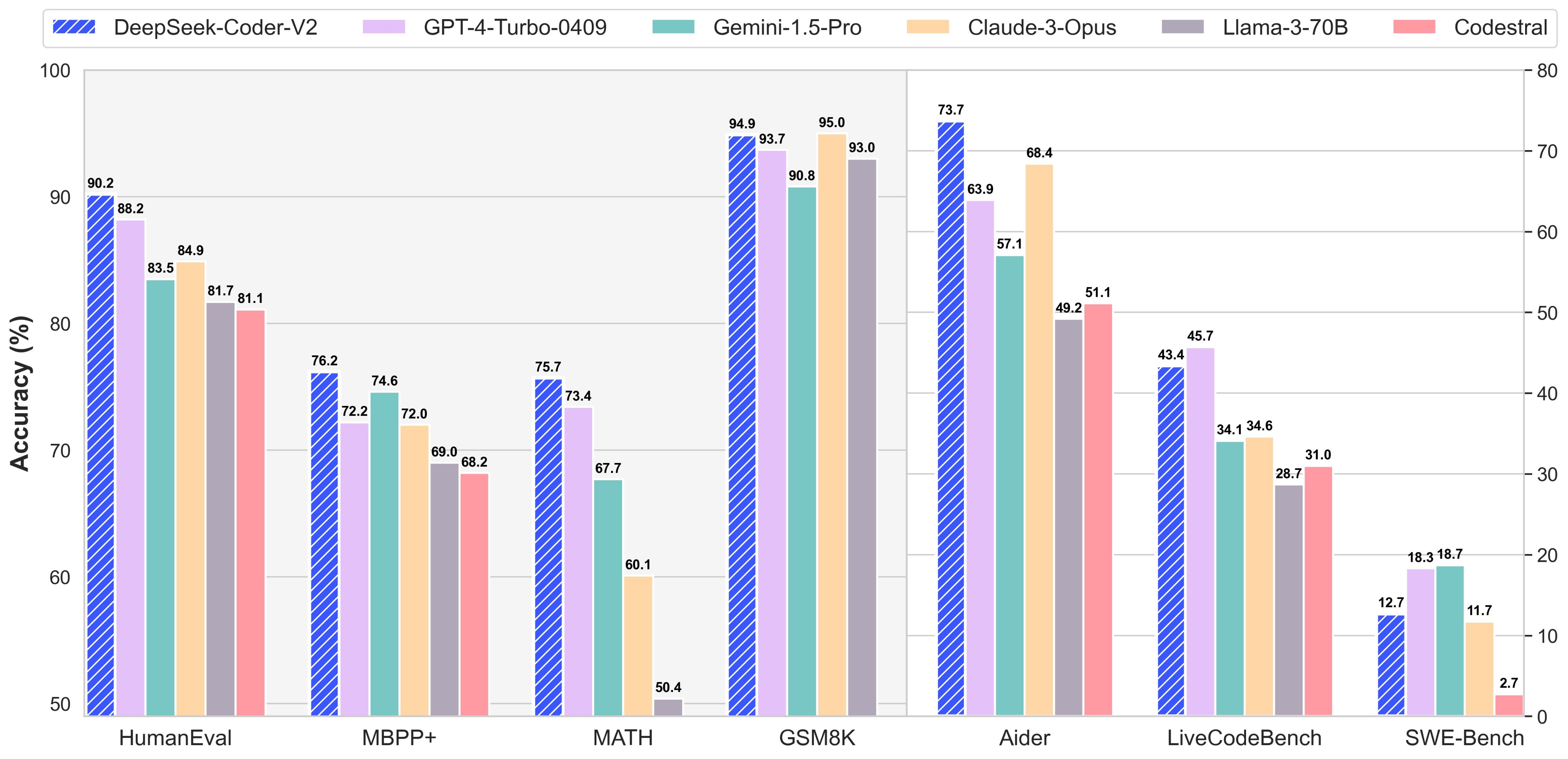
O Coder V2, desenvolvido pela chinesa DeepSeek, foi treinado com mais de 300 linguagens de programação, alcançando pontuações de 90,2 e 76,2 nos benchmarks HumanEval e MBPP+, respectivamente, seguido pelo modelo da OpenAI com 88,2 e 72,2. O Coder V2 utiliza o conceito de MoE (Mixture of Experts), no qual submodelos, ou “especialistas”, são designados para resolver um problema específico, dividindo diferentes partes de uma tarefa entre si. As informações são do site VentureBeat.
O modelo pode ser acessado pelo site da DeepSeek: https://chat.deepseek.com/